groundcover Zero-Instrumentation Observability for LLM Apps
Learn how to monitor and troubleshoot LLM apps with groundcover’s zero-instrumentation observability for secure, cost-effective AI workflows.

The Race for Modern LLM and Agent-Based Workflows
In just a few short years, large language models (LLMs) have gone from research curiosities to the backbone of a new wave of software experiences. AI agents and LLM-powered workflows are being embedded into applications across industries — from customer support bots that resolve tickets autonomously, to developer assistants that generate code, to knowledge engines that augment internal teams with instant insights.
The appeal is obvious. With a single API call, organizations can unlock sophisticated AI behaviors that once required entire ML teams to build and maintain. AI agents can be stitched into existing applications with remarkable ease, delivering instant business value and expanding product capabilities almost overnight.
But as with any transformative technology, speed of adoption comes with trade-offs. The very characteristics that make LLMs so powerful — their reliance on multi-turn conversations, probabilistic outputs, and third-party APIs — also introduce new layers of fragility and complexity.
- Performance volatility: Multi-step agent workflows often chain together several LLM calls, external APIs, and business logic. Latency balloons quickly, errors compound, and responses may arrive incomplete or unstructured.
- Unpredictable ROI: Token usage, context windows, and provider-specific pricing create a moving target for cost optimization. Developers rarely have the visibility to control efficiency, leading to runaway bills and poor returns on investment.
- Quality drift: Hallucinations, context loss between turns, and subtle misalignments degrade the reliability of pipelines, undermining user trust.
- Security and compliance risks: Prompts often contain sensitive information. Personally identifiable information (PII) can slip into payloads. Meanwhile, open-ended input makes systems vulnerable to prompt injections and data leakage.
What emerges is a paradox: organizations are rushing to productionize LLM workflows because of their immense value, but they are doing so without the observability guardrails that modern engineering teams take for granted in every other part of the stack. AI engineers are flying blind — unable to monitor, secure, or meaningfully improve the performance of the very systems they are betting their product on.
It’s a gap that demands urgent attention. And it’s why the conversation around LLM observability has become one of the most important in the AI ecosystem today.
Application Performance Monitoring for LLMs
If this problem feels familiar, that’s because it is. Software engineers have been here before.
More than a decade ago, the rise of cloud-native applications and distributed architectures made it impossible to manage performance without a new category of tools called Application Performance Monitoring (APM). By tracking golden signals like error rates, throughput, and latency across APIs and internal communication flows, APM became the backbone of modern DevOps and Site Reliability Engineering (SRE). It gave teams the visibility they needed to detect incidents, troubleshoot issues, and ensure reliable performance at scale.
For much of its history, monitoring ML workloads required a completely different playbook. Homegrown pipelines, custom deployment strategies, and model-specific metrics meant every team had to reinvent observability for their unique stack.
But in the last two years, everything changed. AI went SaaS. Instead of training and deploying bespoke models, companies increasingly consume the power of AI as an API — directly from OpenAI, Anthropic, Cohere, or any number of providers. That shift reframes the challenge: LLMs are no longer exotic black boxes. They’re SaaS APIs, just like your payments provider, your CRM, or your messaging service.
On paper, this suggests a simple solution. Why not apply the proven methodology of APM to monitor AI usage? Track latency, error rates, and request flows for your LLMs in the same way you would for your databases or customer-facing endpoints.
But in practice, a massive obstacle stands in the way: instrumentation.
Modern APM depends on inserting software development kits (SDKs) or agents into every layer of your stack. This process is brittle, inconsistent, and slow:
- Pre-planning required: Teams must decide what to measure in advance and wire that instrumentation into code, lengthening development cycles.
- Stack dependencies: Each programming language and framework requires its own instrumentation strategy. Teams with heterogeneous stacks face an endless sprawl of methods and an even longer journey to value.
- All-or-nothing coverage: To get real value, everything must be instrumented. Partial visibility often means incomplete answers, but achieving total coverage in a real-world organization is nearly impossible.
In short, traditional APM cannot keep pace with the speed of AI adoption. Teams are spinning up LLM-powered features in weeks, sometimes days. They don’t have the bandwidth to spend months retrofitting their codebases just to gain visibility.
The result? Most LLM-powered applications today are running in production without observability. They are unmonitored, ungoverned, and unsecured. And when forced to choose, organizations almost always prioritize business value over governance and compliance.
To solve this, a new category of observability is required. One that acknowledges the unique characteristics of LLM workflows. One that delivers instant visibility without slowing developers down. One that requires no instrumentation at all.
That’s where groundcover’s LLM Observability comes in — a zero-instrumentation approach to monitoring and troubleshooting that gives teams the control they need, without asking them to compromise on speed.
Secure, end-to-end visibility for LLM and agentic applications
The challenges of monitoring LLM-powered workflows call for a fresh approach. Traditional APM tools weren’t built with multi-turn agents, probabilistic outputs, and sensitive SaaS-based AI APIs in mind. They require heavy instrumentation, trade off on security, and often force organizations into rigid pricing models.
Zero Instrumentation with eBPF
Unlike other platforms, groundcover uses eBPF (extended Berkeley Packet Filter) to achieve full visibility into every API request and response. That means no SDKs, no code changes, and no brittle integrations. By operating at the infrastructure layer, groundcover can automatically monitor every interaction with your LLMs, capturing:
- Full request prompt and model response payloads
- Token usage and costs
- Latency, throughput, and error patterns
The deep visibility provided by eBPF allows the team to go far beyond simple metrics, into insightful observability — following the reasoning path of a failed output, investigating prompt drift across a session, or pinpointing where a tool call introduced latency or degraded response quality.
This is not just monitoring. It’s a way to understand how your AI behaves in production, without slowing developers down or requiring rework.
Built on BYOC, Not 3rd Parties
groundcover’s architecture is based on Bring Your Own Cloud (BYOC). That means all monitoring data — including potentially sensitive prompts and responses — never leaves your cloud environment.
This model ensures:
- Security: PII or sensitive business data isn’t exposed to external vendors.
- Compliance: Data residency requirements are respected by default.
- Trust: Organizations stay in full control of their AI observability pipeline, which has a potential direct impact on their own customers.
Fair, All-Inclusive Pricing
Traditional monitoring platforms often impose request limits or charge extra for AI-focused features.
groundcover goes directly against that model. LLM observability is included by default in our single-skew product and is now available for free to all of our customers.
No request limits, no quotas, no hidden add-ons.
Keeping data on-premise in the most cost-effective manner also allows organizations to monitor more of their LLM workloads with no rate limits or sampling. This translates directly to business value and LLM-related endpoints become more and more prominent in their stack.

Designed for real-world LLM workflows
The age of single-turn LLMs is over. Today’s AI systems rely on multi-turn agents, retrieval-augmented pipelines, and tool-augmented workflows that make debugging and optimization much harder. Monitoring token usage and latency is no longer enough. You need to understand why an LLM response fails, how context drifts across turns, or when an agent misuses a tool.
Protect LLM pipelines from data exposure and security risks
All data captured by groundcover stays within your environment. There's no third-party storage, no outbound traffic, and no risk of exposing sensitive prompts that contain PII, completions, or user inputs. You maintain full control over data residency and compliance, with no trade-off on visibility.
This model is ideal for teams working with regulated data, internal copilots, or user-generated prompts, where security, privacy, and compliance are non-negotiable.
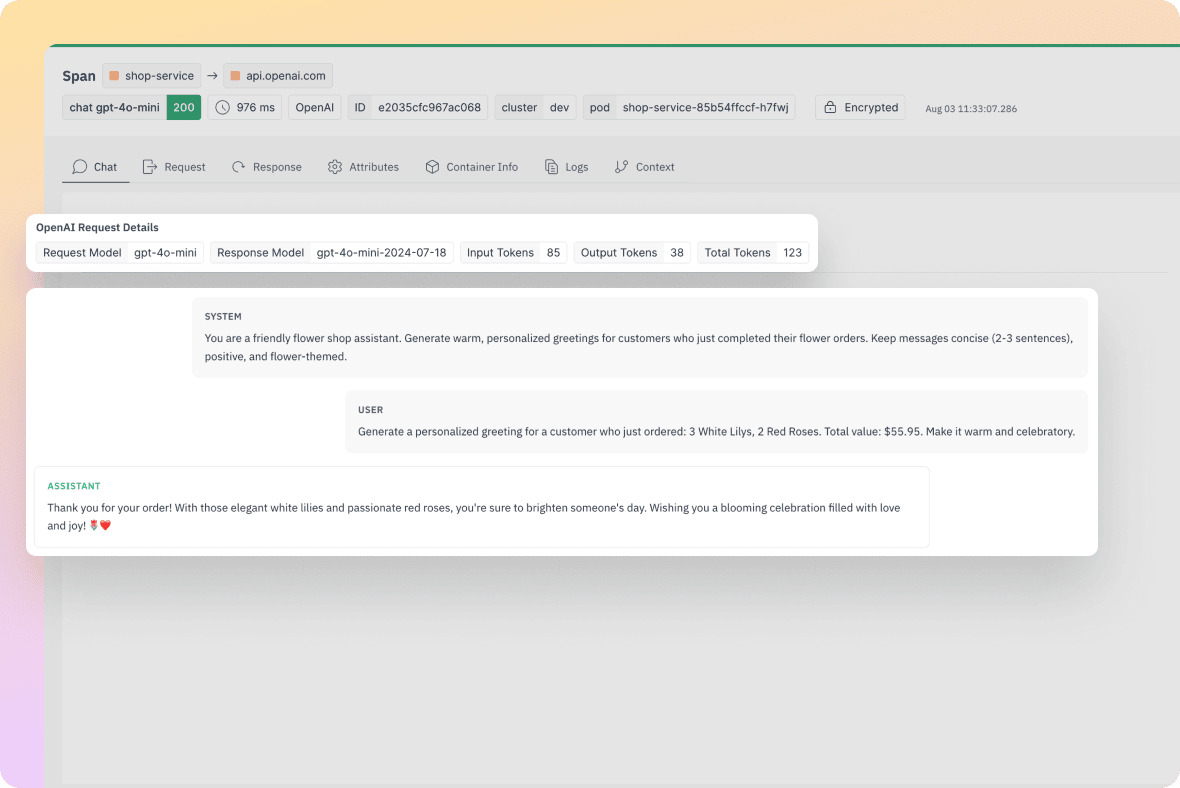
Improve performance and manage LLM spend
LLM workloads can be unpredictable and expensive. groundcover gives you instant access to token usage, latency, throughput, and error rates across every LLM interaction. Without writing a single line of code, you can pinpoint your most token-heavy use cases, track inefficient flows, and uncover hidden opportunities to reduce cost and improve response times. All insights are delivered out of the box, so you can move fast and optimize confidently.
.png)
Monitor LLM responses with full execution context
LLM responses rarely fail in isolation. groundcover captures the complete execution context behind every request including prompts, response payloads, tool usage, and session history so you can trace quality issues back to their source. Whether you're debugging hallucinations, drift, or inconsistent output, you’ll see not just what went wrong, but how and why it happened. This context is key to maintaining output quality in real-world, production environments.
.png)
.jpg)
.jpg)










.svg)