Postgres in Kubernetes: How to Deploy, Scale, and Manage
Learn how to run and scale Postgres in Kubernetes. Explore key setup steps, best practices, and low-overhead observability using groundcover.
.jpg)
Last Updated: May 22, 2026
If you were asked to list the best types of workloads to deploy on Kubernetes, PostgreSQL databases probably wouldn’t be the first to come to mind. As a type of stateful workload (meaning one that requires persistent storage), Postgres can be more complicated to deploy with Kubernetes than simpler apps. You might be tempted to use Kubernetes to host just your applications, and let them interact with a Postgres database that is external to the Kubernetes cluster.
Yet, there are some excellent reasons to consider running Postgres directly within Kubernetes. Here’s a look at them, along with details on how Postgres in Kubernetes works, what the potential drawbacks to this type of Postgres deployment are, and how to manage a Postgres database hosted on Kubernetes.
What is Postgres in Kubernetes?
Postgres in Kubernetes is a PostgreSQL database that runs within a Kubernetes cluster.
PostgreSQL (or Postgres for short) is a popular type of open source relational database. When you run Postgres in Kubernetes, you host the database management software, as well as the data itself, within Kubernetes.
This is not the only way to deploy Postgres, of course. You can also run Postgres directly on a server, without using Kubernetes. Alternatively, you could rely on a managed Postgres service (like Amazon RDS), which provides access to Postgres database instances that are hosted and managed by a third party.
But when you opt for Postgres in Kubernetes, you’re deploying PostgreSQL within Kubernetes. We’ll say more in a bit about why you might want to do this.
Key architectural concepts for Postgres in Kubernetes
First, let’s look at how Postgres in Kubernetes works. The easiest way to explain is to walk through the main architectural components of a Kubernetes-based PostgreSQL deployment.
Pods
A Pod in Kubernetes is one or more containers that host a given workload. When running Postgres, you’d deploy the Postgres software as a Pod.
Persistent Volume Claims
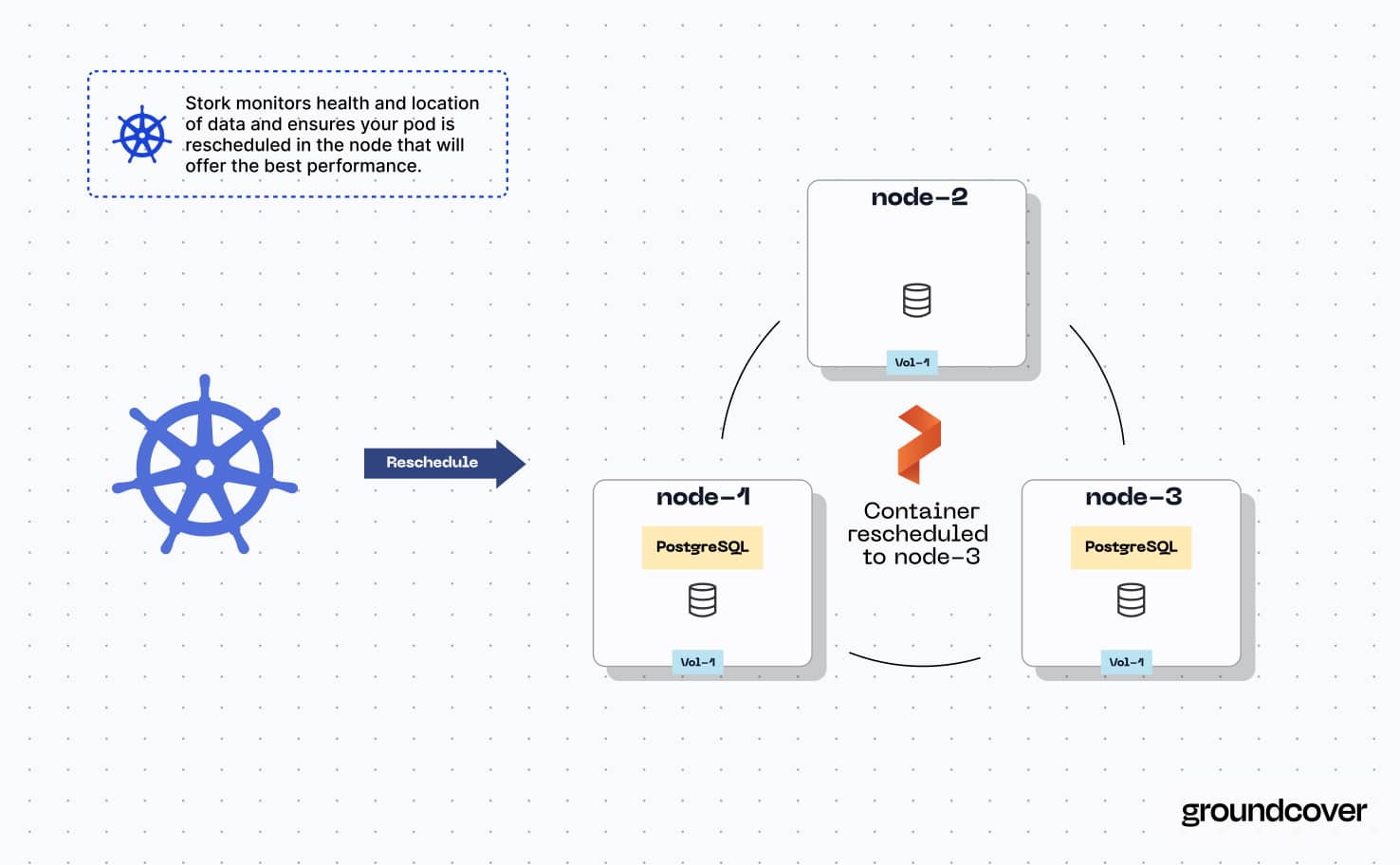
Because PostgreSQL is one of the stateful workloads that keeps persistent local state, the ephemeral nature of Kubernetes pods makes data persistence a challenge and requires access to persistent storage resources. Kubernetes provides these Persistent Volume Claims (PVCs). A PVC allows a Kubernetes Pod to access a storage resource (called a Persistent Volume) that is managed by Kubernetes, and PVs provide long-term storage for PostgreSQL data across pod rescheduling or failures.
When running PostgreSQL, a PVC provides PostgreSQL Pods with access to storage space needed to store Postgres data. You’ll want to ensure that the PV linked to the PVC is big enough to accommodate however much data you’ll be writing to your database, of course. Reliable block storage also matters because pod rescheduling can disrupt I/O performance.
StatefulSets
A StatefulSet is a way of deploying a Kubernetes application such that the application has a unique identifier. For Postgres in Kubernetes, this is important because maintaining a unique ID allows containers that host the Postgres database management software to access persistent storage resources in a consistent way.
If you ran Postgres as a Deployment (a more generic way of deploying applications in Kubernetes) rather than a StatefulSet, your PostgreSQL instances would receive a new, random ID whenever it restarts. Thus, you wouldn’t be able to maintain a consistent linkage to the storage resources that host Postgres data. For the nitty-gritty details of different deployment approaches in Kubernetes, check out our articles on Kubernetes StatefulSet vs. Deployment and Kubernetes deployment strategies.
ConfigMaps, secrets, and environment variables
The easiest way to manage configuration data for Postgres in Kubernetes is to rely on a combination of ConfigMaps, secrets, and environment variables.
ConfigMaps store standard configuration data as key-value pairs. You can use a ConfigMap to define options like your database name and database username.
Secrets allow you to store sensitive data securely, including PostgreSQL credentials such as the postgres user password. Authorized applications should access those credentials through Kubernetes Secrets instead of hardcoding them.
Environment variables, which can be configured when deploying an application in Kubernetes, are also a way of defining configuration data. Unlike a ConfigMap, however, they’re easy to change on the fly. In general, you’d use an environment variable rather than a ConfigMap to define any non-sensitive data that might need to change regularly. For instance, if you wanted to vary the network port used for your database connection in order to make it harder for malicious users to discover, you could set it via an environment variable instead of baking it into a ConfigMap.
Service
In Kubernetes, a Service is a way to define a stable network identity for applications. Services assign an IP address and DNS name that remain the same even if the Pod stops and restarts. When running Postgres, a Service is useful because it ensures that external applications can connect to the Postgres database with consistent network settings.
How to deploy Postgres on Kubernetes: Step-by-step
Now, let’s take a look at how to deploy Postgres on Kubernetes.
1. Choose a deployment method: Helm, operators, or manual deployment
First, you’ll need to decide how to run Postgres on Kubernetes. There are three options:
- Using Helm, a package manager that lets you run applications with just a few commands.
- Using a Kubernetes operator. Operators are also an automated way of running applications. They provide more control and flexibility than Helm and are usually more reliable for PostgreSQL than relying on a basic StatefulSet alone. Their declarative configuration also lets you define database clusters as YAML that fits standard CI/CD and GitOps workflows. Read more about Helm vs. operators.
- With a manual deployment, meaning you define a Postgres StatefulSet and run it by hand, even though operators typically handle this through declarative YAML. This is the approach we’ll cover below, just to demonstrate the details of how to get Postgres running in Kubernetes.
2. Set up a PVC
To deploy Postgres manually, we first need to create a Persistent Volume Claim (PVC). As noted above, a PVC allows Postgres to access the persistent storage necessary to host a database.
Here’s a simple PVC definition that provides 10 gigabytes of storage space:
To create the PVC, save the configuration to a file (like psg-pvc.yaml), then apply it with:
3. Create StatefulSet
Next, we’ll create a StatefulSet. As we mentioned, a StatefulSet is a way of deploying PostgreSQL Pods with unique identifiers, allowing them to connect consistently to the PVC. Setting explicit requests and limits helps with resource management by making cpu and memory usage more predictable, including memory usage for the database container.
Again, save this code to a file (like pg-statefulset.yaml) and apply it with:
4. Create a Service
Again, a Service exposes applications hosted in Kubernetes to external clients on the network. When running Postgres, having a Service is important because it enables a persistent network identity that applications can use when connecting to the Postgres database.
Here’s a sample Postgres Service definition:
Once again, to apply this configuration, you’d save the code to a file (like ps-service.yaml), then run:
Note that in this example, we’re not assigning a fixed IP address to Postgres. Instead, we’re giving it the network name postgres and creating a clusterIP Service. This makes the database accessible to other Pods inside the same Kubernetes cluster using the assigned network name (which Kubernetes will automatically resolve to whichever internal IP address happens to be assigned to Postgres). Applications outside the Kubernetes cluster won’t be able to connect to the Postgres instance in this case because it has no externally routable IP address. If you wanted to enable network access from outside the Kubernetes cluster, you’d typically create a Load Balancer Service instead of the cluster IP Service in this example.
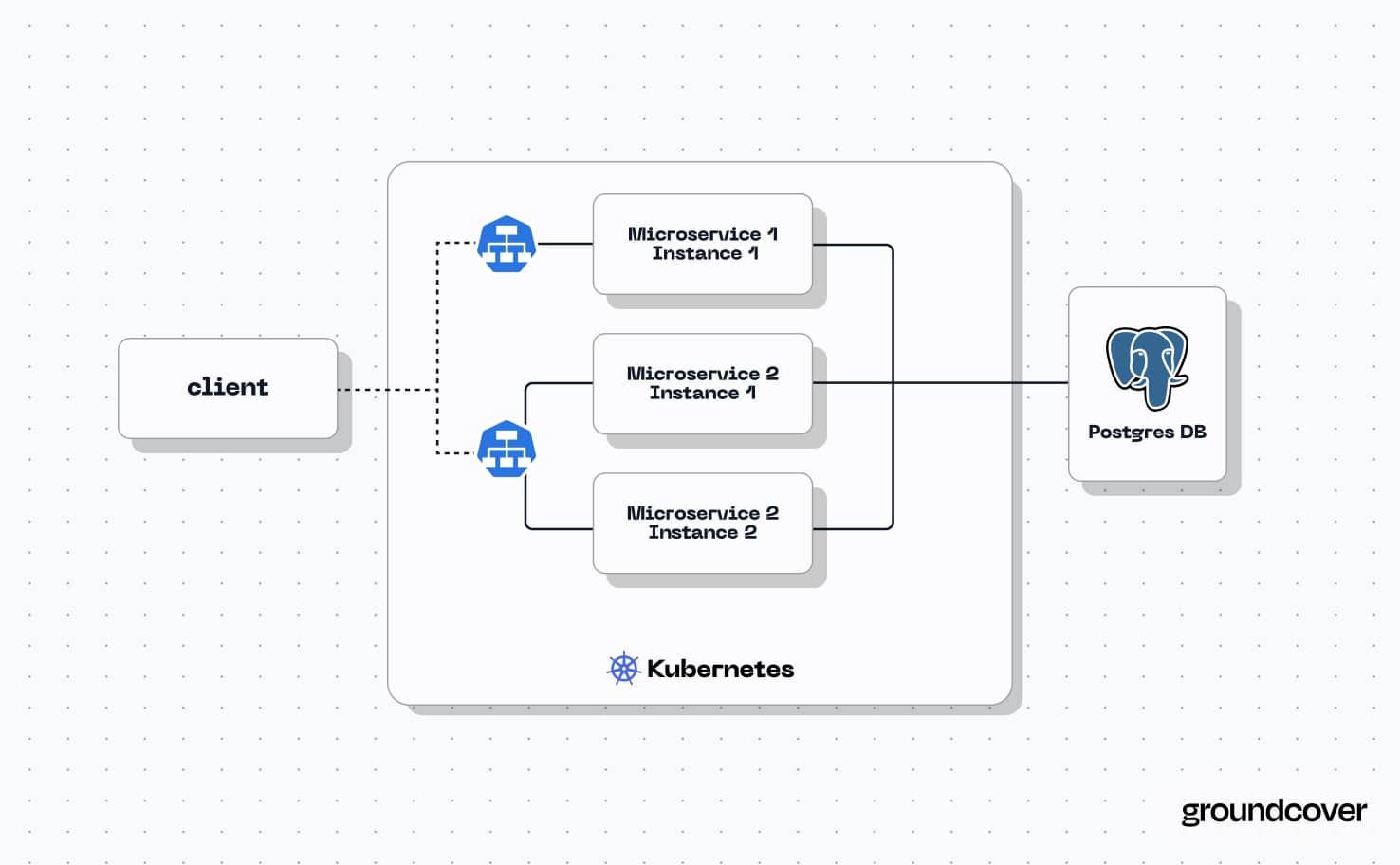
5. Access Postgres
At this point, Postgres should be up and running in your Kubernetes cluster. Applications within the Kubernetes cluster will be able to access it using the network identifier configured in the Service above.
To connect to the database as an administrator, run this command:
This will open a shell with the relevant Postgres access data defined as environment variables inside the shell. From there, you can open a Postgres admin session with:
PostgreSQL Kubernetes operators
As an alternative to deploying Postgres manually, you can also use one of several ready-made Postgres operators. Here’s a look at five popular options:
Postgres Kubernetes Helm charts
Because Postgres is a complex application and Helm works best with simpler applications, it’s generally better to use an operator instead of Helm if you want to deploy Postgres in Kubernetes using an automated approach.
That said, Helm charts (meaning packages that you can deploy using Helm) for Postgres on Kubernetes exist. The main option is a chart provided by Bitnami.
Pros and cons of running Postgres on Kubernetes
Now that we’ve told you how to run Postgres on Kubernetes, let’s talk more about why you may or may not want to do it in the first place.
Pros
The main advantages of hosting Postgres in Kubernetes instead of running it directly on a server is that you get simplified management and scalability. When Postgres runs as a Kubernetes pod, Kubernetes will automatically move the Pod between servers in an effort to ensure the best balance of performance and resource consumption. You can also easily scale Postgres by creating Pod replicas as part of a synchronous replication strategy (we’ll say more about scaling Postgres on Kubernetes and PostgreSQL replication below). With direct-to-server PostgreSQL deployment, you’d have to migrate or replicate the instance manually to manage and scale it.
Hosting Postgres in Kubernetes also provides a convenient way for applications to connect to Postgres without having to send traffic over external networks. As we showed in the PostgreSQL deployment example above, it’s possible to configure a cluster IP, which allows other applications running in your Kubernetes cluster to access Postgres, but doesn’t allow connections from external traffic. And, because Kubernetes manages the name resolution and routing automatically once you create a Service, you don’t need to worry about configuring a separate DNS server or firewall, as you would in most cases if you wanted to run Postgres inside a network-isolated environment without using Kubernetes.
A third benefit is high availability. Since Kubernetes can automatically relocate your Postgres pod in the event that the server hosting it starts to fail, a problem with the host server is less likely to render your database unavailable. You don’t get this level of built-in assurance when running Postgres directly on a server.
Cons
On the other hand, there are drawbacks to hosting Postgres on Kubernetes.
The biggest is the added complexity that comes with having to set up a PVC, StatefulSet, and Service to run Postgres. If you deployed Postgres directly on a server, you’d only need to install the software and define configuration options directly in Postgres. Deploying Postgres in Kubernetes is a more complicated process.
Managing Postgres in Kubernetes can also be more involved because there are more moving parts. For instance, if your database experiences a performance slowdown, it could be because of a bug in Postgres itself, but it could also be caused by a problem within Kubernetes, such as slow internal network routing. This means you have to collect more monitoring and observability data, and assess more possible root causes, when managing Postgres performance.
Use cases for Postgres in Kubernetes environments
To illustrate why you might want to run Postgres in Kubernetes, here’s a look at some common use cases.
High-throughput microservices
Running Postgres directly inside Kubernetes helps to optimize throughput when other applications inside the cluster connect to the database. To achieve very high levels of performance, consider running Postgres in the same cluster as your applications, especially for cloud native applications. When many microservices open concurrent connections, use a connection pooler such as PgBouncer to manage high connection counts between the apps and the database.
Accessing Postgres for platform engineering
Hosting Postgres inside Kubernetes is a simple way to make Postgres available as a service. This can be useful as part of a platform engineering effort, where an organization wants to allow developers to spin up PostgreSQL instances quickly and easily, usually through declarative configuration in YAML rather than manual scripting. By configuring Postgres as an application that runs in Kubernetes, a platform engineering team can make it easily accessible on a self-service basis.
Multi-tenant architectures
Running Postgres in Kubernetes helps to simplify multi-tenant scenarios, meaning ones where multiple users or teams need to access the same database. If those teams also have access to the Kubernetes cluster where Postgres resides, they can easily spin up applications that connect to Postgres.
When not to run PostgreSQL on Kubernetes
In contrast, here are some scenarios where it typically makes less sense to deploy Postgres on Kubernetes:
- Ultra-low latency: Although running Postgres and Postgres client apps in the same cluster can improve performance, it may not suffice if you need ultra-low latency. In that case, running the database and apps on the same bare-metal server is likely to yield better performance, since data won’t have to move between servers at all.
- Lack of in-house Kubernetes expertise: If your business has limited experience managing Kubernetes, it makes more sense to stick with a different deployment option for Postgres. As we said, Kubernetes adds some complexity, and teams without Kubernetes experience may struggle to configure and manage Postgres effectively on Kubernetes.
- Limited Postgres experience: Similarly, if your organization doesn’t have experience working with Postgres, you may want to use a managed Postgres service instead. That way, you can outsource most aspects of setup and monitoring to a database provider.
Scaling Kubernetes PostgreSQL
As we mentioned, running PostgreSQL instances in Kubernetes also makes it easy to scale your database instance.
There are two ways to scale a resource in Kubernetes:
- Vertical scaling, which increases the CPU and/or memory available to a workload.
- Horizontal scaling, which spreads the workload across more servers.
In Kubernetes, you can scale Postgres vertically by changing the requests and limits assigned to your Postgres instance. Requests and limits control how much CPU and memory an application can access, so you can simply allocate more if you want to scale vertically. Storage performance matters too, and high-performance local NVMe-backed storage classes can be a good option when native streaming replication is responsible for data safety.
To scale horizontally, you can create replicas within the StatefulSet that hosts Postgres. You do this by simply adding a replicas: option to the spec: section of the StatefulSet definition. Replicas create additional instances of Postgres.
Note, however, that adding replicas won’t create more copies of your database; it will only add instances of the Postgres management software so that if one goes down, the database will remain available. If you want to copy the data itself for backup and disaster recovery purposes (or as a way of deploying a Postgres cluster, meaning you have one Postgres instance managing multiple databases to increase availability), you’d need to clone the PVC assigned to Postgres. Unfortunately, there is not a straightforward or native way to replicate PVCs such that identical copies of the same PVC are attached to the same application - and thus there is also not an easy way to set up a PostgreSQL database cluster on Kubernetes.
Best practices for monitoring Postgres in Kubernetes
The final key aspect of running Postgres on Kubernetes is understanding how to monitor and observe your database. Monitoring is critical for ensuring performance and availability, no matter how you deploy Postgres, but it’s especially important when you run it on a complex platform like Kubernetes.
The following practices can help ensure an effective approach to Postgres monitoring:
- Use Kubernetes-native observability capabilities: To the extent possible, rely on Kubernetes to generate monitoring data. You can do this by, for example, collecting PostgreSQL Pods metrics via Kubernetes to track the health of your PostgreSQL instances. If you are also monitoring other Kubernetes workloads, using Kubernetes-native observability capabilities helps ensure a unified approach to monitoring.
- Use Prometheus and Grafana as the standard monitoring stack: In most environments, Prometheus is the standard choice for collecting metrics and Grafana for visualizing them, giving teams insight into both PostgreSQL and container-level metrics that support PostgreSQL workloads.
- Track Postgres-specific metrics: Building on that stack, it’s also important to monitor database-specific metrics such as pg_stat_activity, pg_stat_database, pg_stat_bgwriter, pg_stat_user_tables and pg_locks. Kubernetes doesn’t collect these directly, so you’ll need monitoring software that can pull this data from Postgres itself.
- Minimize monitoring overhead: As with any monitoring workflow in Kubernetes, it’s a best practice to minimize the overhead associated with metrics and log collection. To that end, consider using eBPF, a hyper-efficient observability framework, instead of traditional monitoring agents, which are resource-hungry.
How groundcover helps monitor Postgres in Kubernetes
Speaking of monitoring Postgres with help from eBPF, let’s talk about groundcover – an observability solution that uses eBPF to collect metrics, logs, and traces from any workload in Kubernetes. This approach minimizes overhead while maximizing visibility.
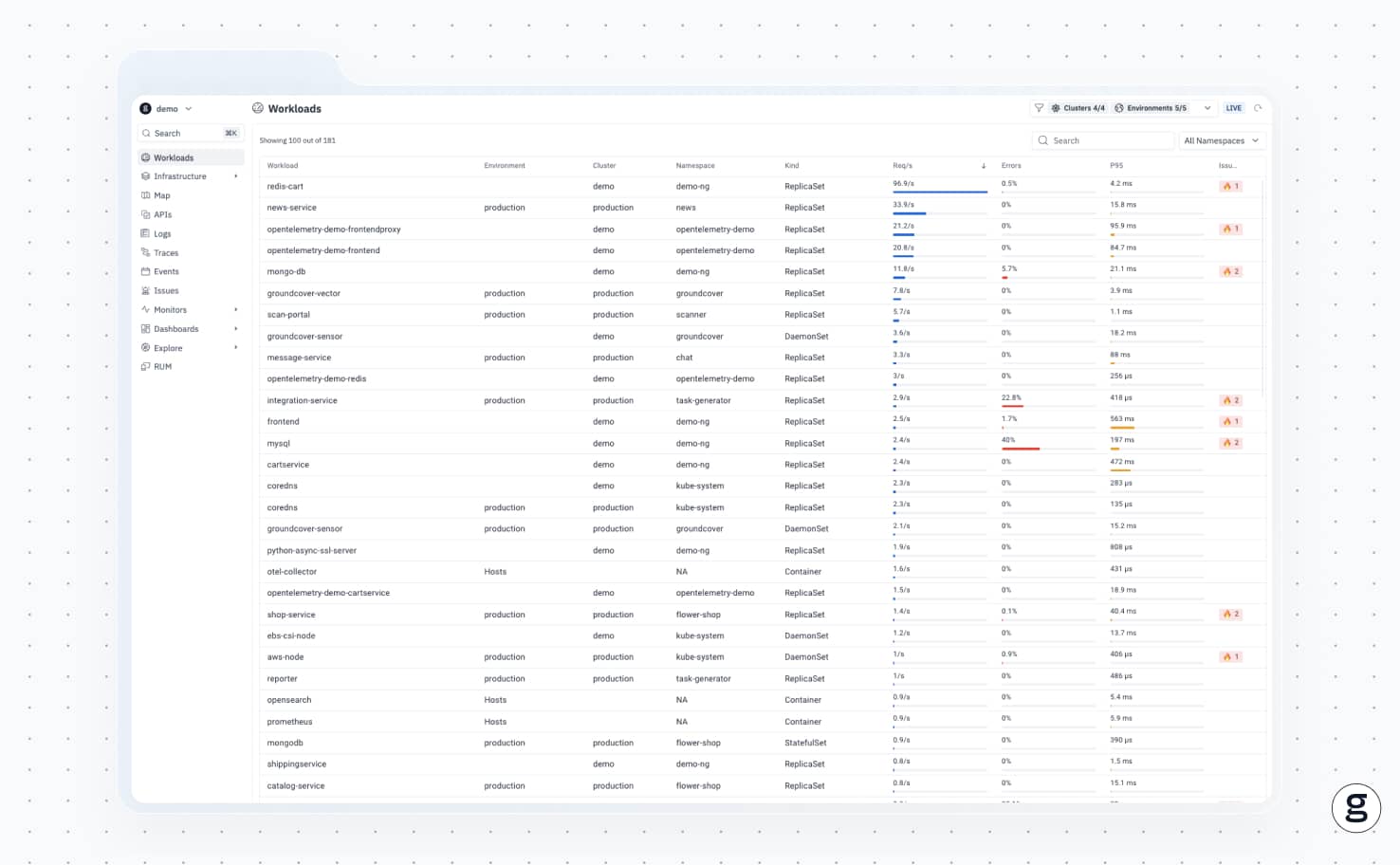
For Postgres workloads, groundcover enables deep insight into what’s happening within all components of your hosting stack – from PostgreSQL pods, to PVCs, to Kubernetes Services, and everything in between. With these insights, you can quickly get to the root of performance issues that impact your databases.
Postgres + Kubernetes: Better together
You don’t need to use Kubernetes to run Postgres. And Postgres is certainly not the only thing you can run on Kubernetes. However, by pairing these two pieces of software, you get a scalable, efficient, customizable means of deploying PostgreSQL, one of the world’s most popular database platforms.
And, with help from an efficient, Kubernetes-native observability solution like groundcover, you can take full advantage of Kubernetes for Postgres deployment while also enjoying the visibility you need to keep everything running smoothly.
.jpg)
.png)
.jpg)










.svg)