Fixing Kubernetes Pod Pending: Causes & Solutions
Find out why pods stay in “Pending” and how to fix them. Learn common causes, smart troubleshooting steps, and practical solutions in our guide.

Last updated on: July 10, 2026
sWhen applications are stuck in the pod pending state, it means that you launched them, but they never actually started due to issues like buggy containers inside the pod or a lack of available nodes for hosting it. It’s sort of like how a seed might fail to sprout because the soil isn’t moist enough or the seed just turns out to be a dud.
We’re not gardeners, and we can’t tell you how to troubleshoot seed issues. But we can tell you all about fixing Kubernetes pod pending problems. Read on for a detailed look at what pod pending means, what causes it, how to detect pod pending issues, and how to resolve them.
Kubernetes Pod Pending: What Does “Pod Pending” Mean in Kubernetes?
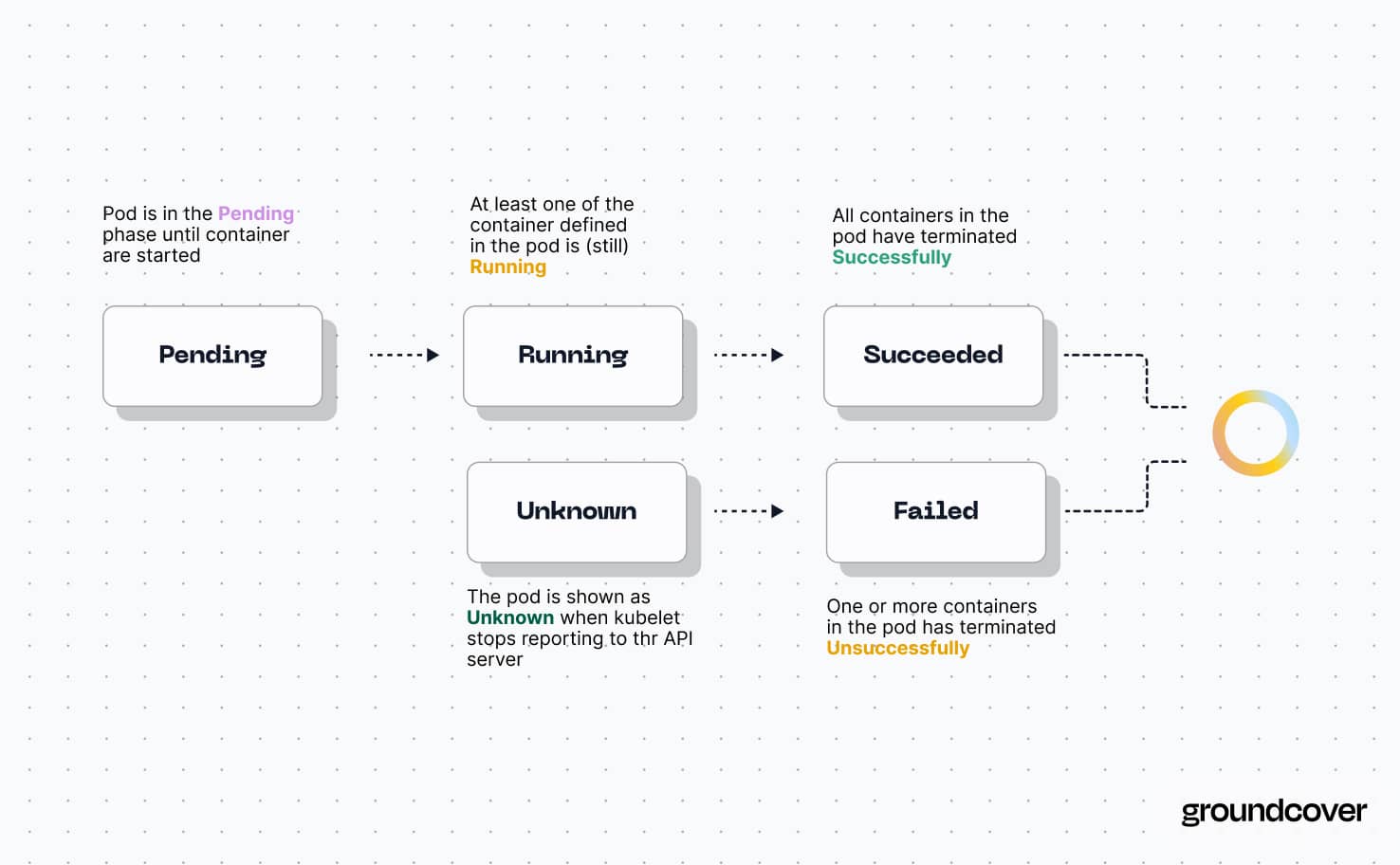
In Kubernetes, “pod pending” is a status indicator that means a pod is waiting to start.
To explain the meaning of pod pending in more detail, let’s step back and talk about what pods are and how they work. In Kubernetes, a pod is one or more containers that host a particular workload. When you run an application in Kubernetes, you typically deploy it as a pod.
Pods can exist in one of five states:
- Pending, which means the pod is still in the process of starting up.
- Running, meaning at least one container in the pod is still operating.
- Succeeded, indicating that the pod has stopped running and all containers in the pod shut down successfully.
- Failed, which happens when one or more containers have shut down unsuccessfully.
- Unknown, a status indicator meaning Kubernetes can’t reach the pod.
For more details, check out our article on K8s container and pod events and status meanings.
You can generate a list of all pods with pending pod status by running:
It’s normal for a pod to be in the pending state for some amount of time – usually, no more than a minute, and often just a few seconds – as part of the standard pod startup process. However, it sometimes happens that a pod gets stuck in the pending phase and never proceeds to running status. This is a problem because if the pod remains pending indefinitely, your workload will never actually start.
Why Kubernetes pods get stuck in the pending phase
If a pod is pending for more than a minute or so, it likely means that some sort of problem is causing it to remain stuck in pending status. Common causes for this error include:
- Lack of available nodes: A pod won’t change to the running phase until the Kubernetes control plane has successfully placed (or “scheduled,” to use the technical term) the pod on a node within the Kubernetes cluster. If no nodes with enough spare CPU and memory are available to host the pod, the pod will remain pending until a node opens up (or until a new node is added to the cluster).
- Node selectors, taints, or affinity rules prevent scheduling: In Kubernetes, node selectors (and node labels), taints (and pod tolerations), and affinity rules each offer ways of requiring pods to be scheduled on certain nodes. This can be desirable if you want to ensure that a certain node or type of node hosts your workload. However, if you configure your pod to run on a specific node or node type and no such node is actually available, the pod ends up pending indefinitely.
- Required volumes can’t be attached: Pods can become stuck in pending if they require a storage volume that Kubernetes can’t attach. This usually happens because the pod requires a persistent volume claim (PVC) that can’t be satisfied, often because the required persistent volume doesn’t exist or is not reachable.
- Failed image pulls: If one or more of the containers inside a pod requires an image that can’t be pulled, the pod will remain pending. Image pulls typically fail because a specified container registry is unreachable or does not exist, or because the name or path to the image within the pod spec point to the wrong image file or location.
- Container startup failures: Pods will remain pending until all containers inside them have successfully started. If a container fails to start due to a problem like buggy code or insufficient resources, the pod will be stuck with pending status.
Advanced scheduling behaviors that impact pod pending status
The problems we just covered are the most common causes for pods to be stuck in pending. In some cases, however, more complex issues related to the way the Kubernetes control plane handles scheduling can cause pending problems. These include:
- Pod priority and preemption: Pods can optionally be assigned priority classes. If insufficient nodes are available to support a pod in a high-priority class, Kubernetes will stop lower-priority pods through a process known as preemption. Preemption can cause the lower-priority pods to return to the pending state until enough resources free up to support them.
- DaemonSet challenges: A DaemonSet is a way of running a pod across all nodes within the Kubernetes cluster, or on specific nodes. If the requirements defined in a DaemonSet can’t be satisfied for every node (which could happen if, for example, there are insufficient resources available on all nodes), the DaemonSet’s pods will be stuck in pending.
- Pod affinity and anti-affinity conflicts: You can define affinity rules that require different pods to be scheduled on the same node. You can also set anti-affinity rules that prevent two or more pods from being scheduled on the same node. In both cases, the inability of the scheduler to find available nodes that have both the resources necessary to host a pod and that satisfy the pod’s affinity or anti-affinity rules could result in indefinite pending status.
- Pod update delays: There are multiple ways to manage pod updates as part of a Kubernetes deployment strategy or when restarting Kubernetes pods. Some approaches (such as rolling updates, which replace older pod instances with new versions) can cause pods to get stuck in pending when resource over-commitment increases competition for resources, too many pods create resource constraints, and no nodes are available for scheduling the updated version of the pod.
If you encounter pending problems that can’t be explained by simpler issues, like the exhaustion of total cluster node capacity or problematic node selectors, it’s likely that one of the more complex scheduling rules described above is the reason your pod is not entering running status.
Troubleshooting pending pods in Kubernetes
To troubleshoot a pod that is stuck in pending, start by troubleshooting pods stuck with the following steps.
1. Use kubectl describe pod for quick diagnosis
First, run the kubectl describe pod pod-name command (being sure to replace pod-name with the actual name of the pod you are troubleshooting).
The command provides detailed information about the pod, including a section labeled “Events” with listings of Kubernetes events related to it. Running it reveals the events indicating why scheduling failed. For example, an event that mentions FailedScheduling with a message about nodes not being available is an indicator that the pod can't be scheduled because there are not sufficient nodes to support the pod.
2. Inspect node availability and status
If a pod event suggests that the issue is related to nodes, you can use the kubectl get nodes command to list nodes in your Kubernetes cluster. Verify node health and node conditions to confirm nodes are ready for scheduling. This may be helpful for determining whether there are fewer available nodes than you expected (due to problems like nodes failing and not restarting), which could explain why a pod can't be scheduled because the cluster lacks sufficient resources.
You can also use the kubectl describe node node-name command to get details on the status of a particular node, including any conditions (like taints) that would explain why the node can't schedule specific pods. You can then run kubectl top nodes to review CPU and memory usage and overall resource utilization, though this requires metrics server.
3. Review PVC bindings and storage configuration
If pod events imply that the problem has to do with a PVC or storage settings, use kubectl get pvc and kubectl describe pvc pvc-name to confirm whether storage is actually available to the pod by checking the PVC status (read more about possible causes of PVC issues and how to troubleshoot them). This matters especially for workloads that rely on shared storage.
4. Review pending pod specification
If you can’t find any events that would explain why the pod is stuck in pending, check the pod’s spec (meaning the code that defines the pod’s deployment configuration, such as which containers it includes and which node selector or toleration rules it should follow). You can do this by viewing the YAML code used to deploy the pod by running the following command:
When reviewing the YAML code as the pod description, confirm the live pod spec matches what you intended to deploy. Pay particular attention to the following:
- Whether there are any node selectors, taints, affinity rules, or other restrictions on which specified nodes the pod can run on; the pod stays pending when no matching nodes exist.
- The container images and associated registries used by the pod. Make sure these exist and that there are no typos in them.
- Whether any resource requests are in place that require the pod to have certain amounts of CPU or memory available. If no node has enough cpu or memory resources to satisfy them, the pod can't be scheduled, and reducing requests can help.
It may also be helpful to run the YAML code through a linter, like YAML Lint. This will help catch typos (such as missing indentations) that could cause Kubernetes to misinterpret the pod configuration.
#5. Deploy containers manually
If all else fails, a final troubleshooting step is to deploy the pod's containers manually using a command like docker run. This can help you identify containers that are not starting properly due to problems like buggy code, confirm whether the application is behaving correctly outside Kubernetes, and distinguish those issues from image pull errors.
Fixing Kubernetes pod pending state issues
In most cases, resolving a pending problem with pods in Kubernetes involves one of the following fixes.
Adjust resource requests and limits for pending pods
Changing resource requests and limits can resolve Kubernetes pod pending issues by making it easier for the scheduler to find an appropriate node, since overly high resource requests or restrictive resource limits can keep new pods from being scheduled when nodes are constrained. Specifically, you'll want to reduce the resource requests or eliminate them altogether. Namespace resource quotas or LimitRanges can also stop pods from being created, so check those policies before changing requests.
Correct node selection, affinity, and toleration rules
If your pod can't be scheduled because it includes node selection, affinity rules, or tolerations that don't match existing nodes, including conflicting node taints, the solution is either to drop the restrictions from your pod configuration or to add nodes that satisfy the requirements. Pods can also remain pending when specified nodes are cordoned as unschedulable nodes or are otherwise unavailable. For instance, you may need to add a taint to more nodes if a pod has a toleration that corresponds to the taint, helping prevent pods from remaining pending by aligning tolerations and placement rules with actual node availability.
Resolve storage and PVC conflicts in pending pods
In cases where a container image can't be pulled due to image pull errors, the fix is usually to correct the name of the image or the path to it. You may also need to update the registry URL, if it's incorrect or has moved. In some cases, changing the container image tag can also resolve the problem if the registry no longer contains the version you originally specified.
Verify container image names and URLs
In cases where a container image can’t be pulled, the fix is usually to correct the name of the image or the path to it. You may also need to update the registry URL, if it’s incorrect or has moved. In some cases, changing the container image tag can also resolve the problem if the registry no longer contains the version you originally specified.
Add node capacity to the cluster
Adding or freeing node capacity can resolve pending problems with pods by providing more resources for scheduling when nodes lack sufficient CPU or memory. There are two ways to do this: Either you can add more nodes to the cluster, or you can stop or scale down existing workloads (by, for example, modifying ReplicaSet configurations) to free up node resources. High memory usage or insufficient cpu on current nodes are common signs that cluster scaling is the right fix, and cluster autoscaling can dynamically add capacity when scheduling is blocked by insufficient resources.
Best practices for preventing pending problems in pods
To minimize the risk of experiencing pod pending issues in the first place, consider the following best practices for working with pods:
- Monitor node capacity: First and foremost, monitor your nodes continuously to track overall node and cluster capacity, identify failing nodes, monitor how pods are spread across nodes, and so on; for example, run kubectl top nodes regularly to watch CPU and memory usage over time. Continuous monitoring can also help you spot node health issues, api server-related reporting gaps, and resource contention before pod scheduling fails, which helps prevent pods from getting stuck while resources are still available to fix the problem. The more visibility you have into node status, the better equipped you are to get ahead of issues like running out of sufficient nodes to support your workloads.
- Lint your pod spec: As mentioned above, the simple step of running configuration code through a linter prior to deploying pods can help you catch basic typos that might cause problems like failure to satisfy a toleration or to pull a container image.
- Test deployments in staging before production: Before deploying pods for production purposes, attempt to run them in a testing or staging environment. This will clue you into issues that may prevent the pods from running.
- Use LimitRanges: If you need to control resource allocations but want to avoid having a pod fail to schedule due to a specific resource quota, consider using a LimitRange to manage resources. As the term implies, LimitRanges specify a range of resources. By setting a relatively low minimum threshold, you increase the chances of a pod being schedulable.
- Enforce pod policies using Gatekeeper: You can use an admission webhook like Gatekeeper to require pods to conform to specific policies before admitting them into your cluster. For example, you could block pods that have unsatisfiable tolerations. Although you’ll still end up with a pod that doesn’t successfully start, detecting the issue via a solution like Gatekeeper helps you find the problem early and get more context about it than you could if you simply waited for the pod to be stuck in the pending pod status.
- Consider autoscaling: Autoscaling can help to keep cluster resources in alignment with pod needs. You can configure horizontal autoscaling, which adds pods as demand increases, and vertical autoscaling, which increases the CPU and memory assigned to pods based on need. Some Kubernetes distributions also support cluster autoscaling, which adds nodes as necessary to satisfy pod scheduling and resource requirements.
How groundcover helps troubleshoot pod pending problems
As a comprehensive Kubernetes troubleshooting, monitoring, and observability solution, groundcover offers the visibility and context you need for troubleshooting pods, including pods stuck in the pending state. With groundcover, you can easily collect details on the status of all nodes and pods in your cluster, and visibility into running containers, node conditions, and resource utilization helps identify the root cause faster – whether it's lack of available resources, storage issues, node failures, or complex scheduling behavior.
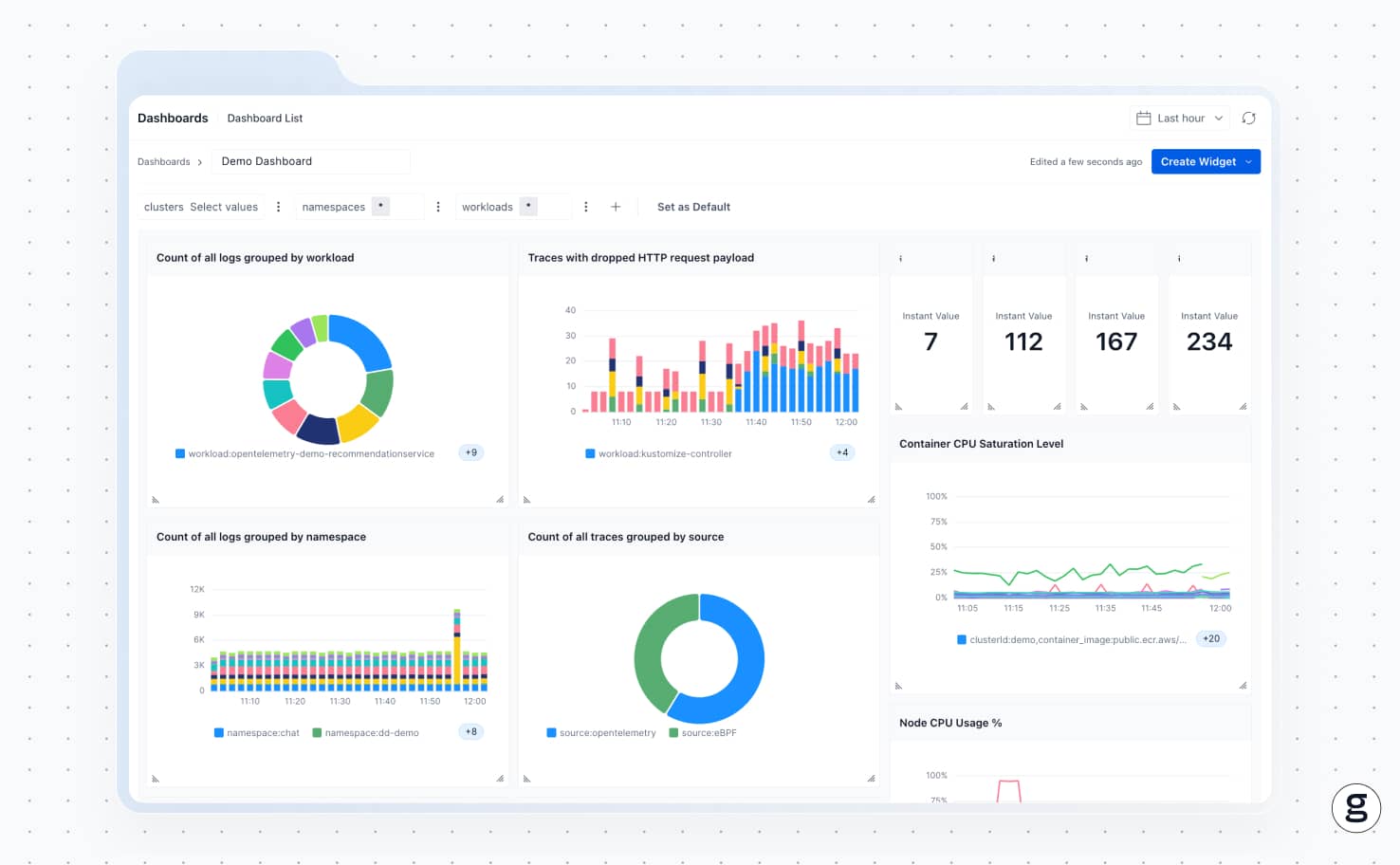
We can’t guarantee that your pods will never end up stuck in the pending state. But we can deliver the insights you need to troubleshoot the problem quickly when it happens.
Getting pending pods to sprout to life
Pod pending problems can be frustrating, especially when a Kubernetes pod stuck or pod stays pending despite your checks. But identifying and resolving them results in the same reward as watching a seed sprout after you thought it was a dud: It brings your pods to life, defying whichever cluster or pod configuration errors were at the root of the pod's initial failure to start successfully.
.jpg)
.png)
.jpg)










.svg)