CrashLoopBackOff
Dive into what CrashLoopBackOff errors mean, why they happen, and how to troubleshoot them so you can get your Kubernetes Pods back up and running quickly once they occur.


CrashLoopBackOff may sound like the name of a 90s grunge band, or possibly a vague reference to an obscure Ringo Starr song from the 1970s. But in actuality, CrashLoopBackOffs have nothing to do with the music industry and everything to do with Kubernetes performance and reliability. For a variety of reasons, Kubernetes Pods can end up in a state known as CrashLoopBackOff, and until you fix it, any applications that depend on those Pods won't run correctly.
Keep reading for a dive into what CrashLoopBackOff errors mean, why they happen and how to troubleshoot them so you can get your Pods back up and running quickly.
What is Kubernetes CrashLoopBackOff?
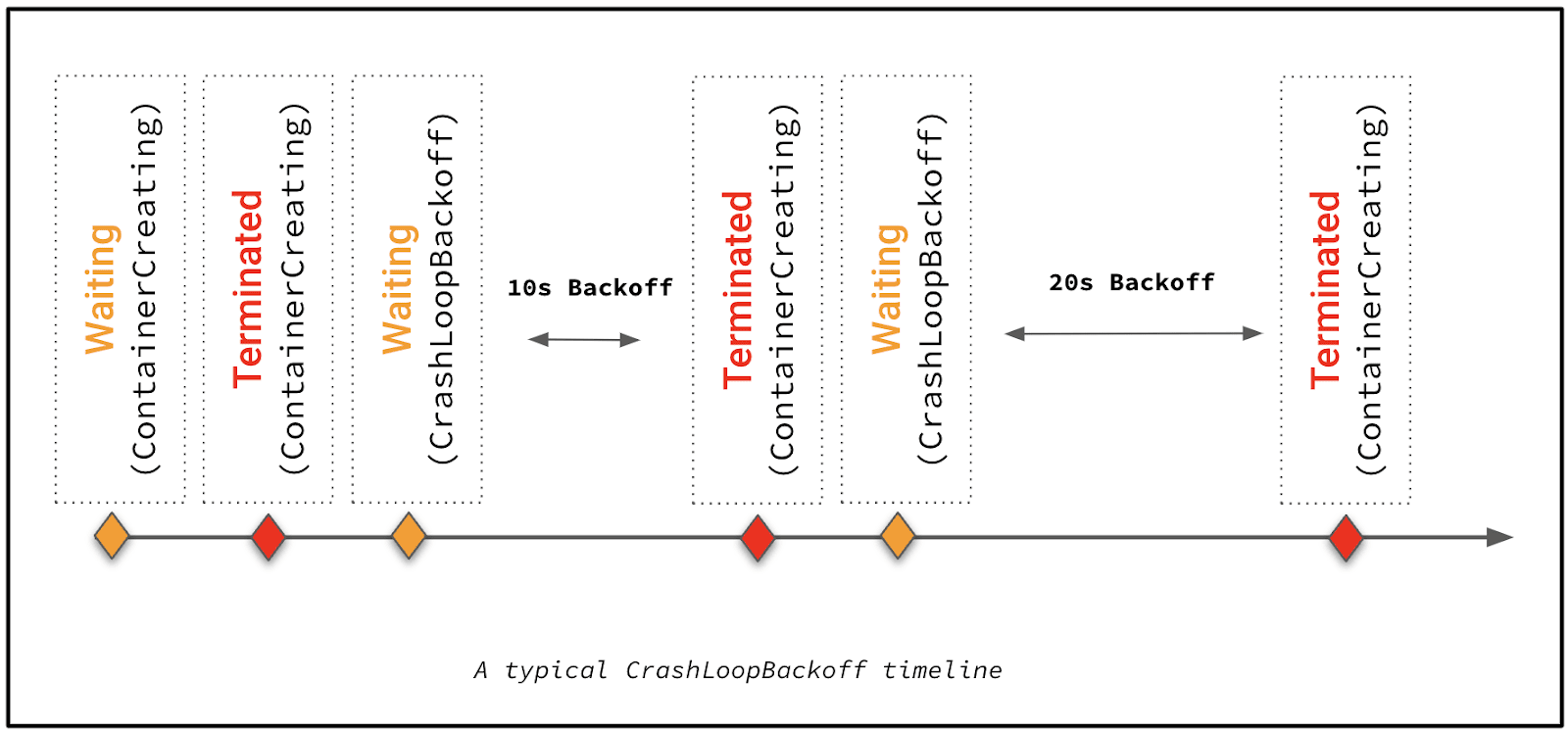
A CrashLoopBackOff error is a condition where containers inside a Kubernetes Pod restart and subsequently crash in a never-ending loop. When this happens, Kubernetes will begin introducing a delay – known as a backoff period – between restarts, in an effort to give admins time to correct whichever issue is triggering the recurring crashes. It also typically generates an error message that mentions "back off restarting failed container."
So, although CrashLoopBackOff may sound like a nonsensical term, it actually makes sense when you think about it: It refers to a state where your containers are in a loop of repeated crashes, with backoff periods introduced between the crashes.
Causes of CrashLoopBackOff/kubernetes-troubleshooting/dns-issues
Although all CrashLoopBackOff states result in the same type of problem – a never-ending loop of crashes – there are many potential causes:
- ImagePullBackOff: Your containers might not be starting properly because an image can't be pulled.
- OutOfMemory (OOM): The containers could be exceeding their allowed memory limits.
- Configuration errors: Configuration issues like improper environment variables or command arguments could be triggering a crash loop.
- Application bugs: Errors in application code could be causing the containers to crash shortly after they start.
- Persistent storage configuration issues: If there is an issue accessing persistent storage volumes – such as a misconfigured path to the resources – containers may not be starting properly.
- Locked resources: Sometimes, a file or database is locked because it's in use by another Pod. This can cause a CrashLoopBackOff if a new Pod attempts to use it.
- Read-only resources: Similarly, resources that are configured to be read-only can cause this error because Pods fail to write to them.
- Invalid permission settings: Misconfigured permissions could make resources unavailable as well, resulting in a CrashLoopBackOff.
- Network connectivity problems: Network issues, which could result either from networking configuration problems or a network failure, could be triggering crashes.
In short, basically any condition that could cause containers to crash right after they start has the potential to create a CrashLoopBackOff. If the containers repeatedly try to restart and repeatedly fail, you get this error.
What does a CrashLoopBackOff error look like in Kubernetes?
No red light starts flashing on your Kubernetes console when a CrashLoopBackOff event occurs. Kubernetes doesn't explicitly warn you about the issue.
But you can figure out that it's happening by checking on the state of your Pods with a command like:
(demo-ng is the namespace we’ll be targeting in this guide. As the name suggests, it’s a demo setup).
If you see results like the following, you'll know you have a CrashLoopBackOff issue:
Specifically, there are two Pods experiencing this issue – the currencyservice and checkoutservice Pods – in the example above.
You may also have a CrashLoopBackOff error if you see Pods that are not in the Ready condition, or that have been restarted a number of times (which you can check by looking at the restart count in the RESTARTS column of the kubectl output). Although those conditions don't necessarily imply a CrashLoopBackOff error, they may constitute one, even if Kubernetes doesn't explicitly describe the Pod status as being CrashLoopBackOff.
How to troubleshoot and fix CrashLoopBackOff errors
Of course, knowing that you have a CrashLoopBackOff issue is only the first step in resolving the problem. You'll need to dig deeper to troubleshoot the cause of CrashLoopBackOff errors and figure out how to resolve them.
Check Pod description with kubectl describe pod
The first step in this process is to get as much information about the Pod as you can using the kubectl describe pod command. For example, if you were troubleshooting the CrashLoopBackOff errors in the checkoutservice-7db49c4d49-7cv5d Pod we saw above, you'd run:
You'd see output like the following:
In reviewing the output, pay particular attention to the following:
- The pod definition.
- The container.
- The image pulled for the container.
- Resources allocated for the container.
- Wrong or missing arguments.
In the example above, you can see that the readiness probe failed. Notice also the Back off restarting failed container message. This is the event linked to the restart loop. There should be just one line even if multiple restarts have happened.
Check Pod events
It's also possible to get this information using the kubectl getevents command:
Which generates output like:
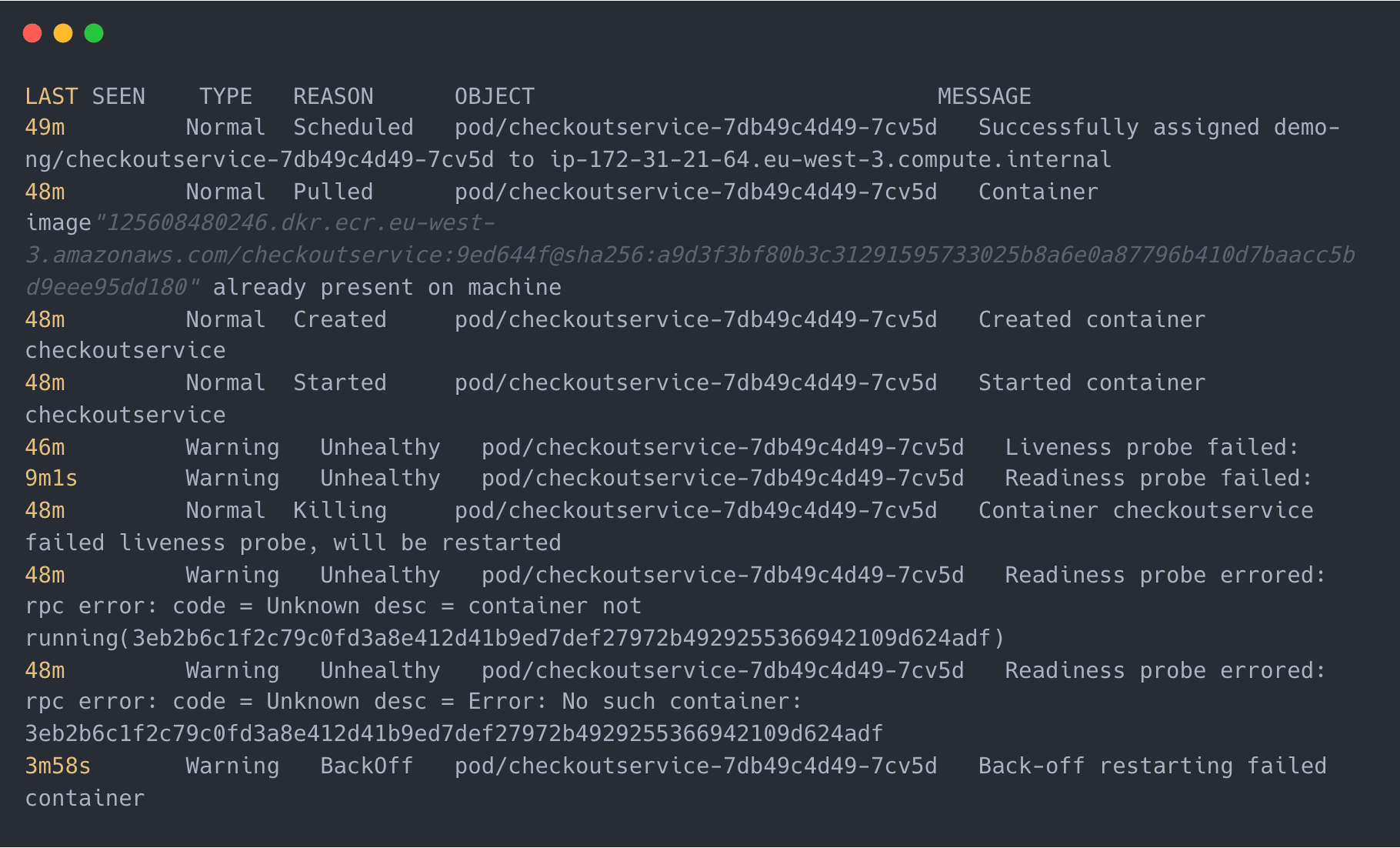
Notice that these are the same messages we got by describing the Pod.
Dig through container and Pod logs with kubectl logs
At this point, we have a sense of why the restarts are happening – they're related to a failed container readiness probe and recurring "back off restarting failed container" restarts – but we still don't know exactly why those things are occurring.
So, let's check the container logs with the kubectl logs command to see if that provides a clue. We run:
Which results in:
Sadly, this could be unhelpful in many cases. But in our case – an application error indicates the root cause of our CrashLoopBackOff – the application is trying to run an unfound script. In this case, that should be focused enough to help us solve the issue, and remediate the CrashLoopBackoff..
Looking at the ReplicaSet
In other cases, where container and Pod logs are unhelpful, we’ll need to keep digging. We can look for more clues by checking out the workload that controls our Pod.
The ReplicaSet controlling our Pod in question might contain a misconfiguration that is causing the CrashLoopBackOff.
When we described the Pod, we saw the following:
This line tells us that the Pod is part of a ReplicaSet. So, investigating the ReplicaSet that controls the Pod by describing the ReplicaSet would look like:
The result might help us catch a deeper configuration in the workload that controls our checkoutservice which could be a good way to continue the investigation.
Troubleshooting CrashLoopBackOff with groundcover
The troubleshooting process we just walked through is the one you'd follow if you enjoy suffering and pain.
If, on the other hand, you enjoy sunshine and rainbows, you'd be better suited by using groundcover to troubleshoot CrashLoopBackOff events. Groundcover continuously monitors all applications and Kubernetes infrastructure components inside your clusters. From one place, you can track events that might indicate a CrashloopBackoff error. You can also compare the number of running Pods to the desired state, you can access the logs from Pod containers and you can view infrastructure monitoring metrics that may indicate memory or CPU issues. With this data, you can more easily get to the root cause of CrashLoopBackOff errors.
As an example, here's how an OutOfMemory issue on a Pod (due to misconfigured resource limits) turns into a CrashLoopBackoff event, and how groundcover surfaces the issue:
Best practices for preventing CrashLoopBackOff errors in Kubernetes
Of course, even better than being able to troubleshoot CrashLoopBackOffs easily is to prevent them in the first place. While you can't foresee every possible CrashLoopBackOff cause every time, you can follow some best practices to reduce your risk of this type of problem.
1. Validate configuration files
Since configuration issues as simple as a single mistyped character could lead to CrashLoopBackOff, validating configuration files before applying them is a good practice for avoiding this type of error.
You can do this using free tools, such as kubectl-validate, that automatically check YAML code. These tools won't validate that any resources referenced inside the YAML code are configured correctly, but they will detect typos and formatting problems (such as improper indentation) that could muck up your Pod configurations and lead to recurring crashes.
2. Test container images prior to deployment
Another simple way to prevent many basic CrashLoopBackOff events is to test container images manually before deploying them in Kubernetes.
To do this, first run a Docker command to see whether you can pull the image that a Pod uses:
Make sure that you specify the same image name and version as the one referenced in your Pod, that you’re pulling the image from the same registry, and that you’re running the operation from the same node that will host your Pod. If a manual image pull fails, you likely either have misconfigured image settings or a networking issue that is preventing access to the image. It's also possible that access control restrictions within the image registry are preventing you from pulling the image.
If the image pull is successful, you can test whether you’re able to start a container using the image with:
Trying to start a container manually helps to rule out problems like bugs inside the container image or corrupt image files, which could cause CrashLoopBackOffs if you attempt to run a Pod that uses the same image.
3. Check environment variables
Since misconfigured environment variables are a possible cause of CrashLoopBackOff, checking environment variable settings is a best practice for catching potential problems.
You can list environment variables by execing into a container and running the following command:
The output will display environment variables and their values. Look for any values that are empty or that don't match expected configuration.
4. Configure proper resource limits
Resource limits that are too low could result in a situation where a container fails to start because it can't access enough CPU or memory resources.
We can't tell you exactly which resource limits to set, since every Pod is unique. But we can tell you that by monitoring Pod resource consumption trends over time using a handy tool like groundcover, you can set reasonable limits that prevent your Pod from hogging too many resources, while simultaneously ensuring it has enough resources available to start up properly.
Bear in mind that Pods may consume more resources during startup during normal operation, since startup often involves carrying out a variety of special tasks – so be sure to set limits that are high enough to support the consumption spikes that occur at startup, not ones that simply support baseline operation.
#5. Monitor network connectivity
Make sure that resources in your Kubernetes cluster have network connectivity. There is no single command you can run to check all aspects of your networking configuration, but you can start by ensuring that the node that hosts a crashing Pod has connectivity. To do this, first run:
The output will display information about Pods, including the node that hosts them. With that information, try SSHing into the node and using commands like ping and host to check its connectivity.
You can also try starting the containers that are experiencing issues directly on the command line using a command like:
Once the container is running, exec into it to open a shell inside the container. From there, check whether the container can access the network. This allows you to determine whether any buggy code inside the container, or problematic startup commands, are causing network connectivity issues.
6. Check DNS configuration
If your network appears to be operating normally but your Pods are still crashing, problems with DNS – specifically kube-dns, the Kubernetes built-in DNS service – could be the issue. Check that DNS names are resolving properly by running:
This will display a list of endpoints and their network addresses. If a resource that your Pods depend on has an address that isn't visible, DNS issues are likely the cause of your CrashLoopBackOff error.
7. Monitor persistent storage
To check that persistent storage resources used by Pods experiencing a CrashLoopBackOff are configured correctly, run:
If persistent volumes appear properly configured but your Pod is still having trouble accessing storage resources, check the underlying filesystem to make sure it is not configured in a way that is preventing access.
You can use the following command on the Linux CLI to check the permissions for individual files and directories:
In addition, you can find information about the status of mounted partitions or file systems – including whether any are mounted read-only – with this Linux command:
8. Validate third-party services
If your Pod depends on a third-party service – meaning a service that is external to the Kubernetes cluster – an inability to reach the service could trigger a CrashLoopBackOff. You can't check for this kind of issue by inspecting cluster resources because the third-party service is outside your cluster.
But you can attempt to connect to the service manually to check whether it's reachable. For instance, if the service is available at a URL, try execing into the container and running a curl command like the following:
If the service is unreachable, the most likely cause is a networking configuration problem. But it's also possible the service is simply down, or that the path to it is misconfigured.
9. Implement robust error handling
Robust error handling provides clear feedback when a bug prevents an application from starting properly. Implementing robust error handling requires writing application logic that generates exceptions when the normal flow of the application is disrupted.
Implementing error handling can be a lot of work, since it involves updating application code. But if you've done everything else to prevent CrashLoopBackOffs and are still running into issues, changing the code is a good final step to try.
Back off, CrashLoopBackOffs
In a perfect world, your containers and Pods would start perfectly every time.
In the real world, the best laid plans of Kubernetes admins don't go as you expect. And sometimes, unexpected errors result in CrashLoopBackOff states for your Pods.
Fortunately, you can find the root cause of such errors easily enough with a little help from kubectl – or, better, from a tool like groundcover, which provides deep, continuous visibility into containers, Pods and everything else inside your Kubernetes clusters.
Check out our Kubernetes Troubleshooting Guide for more errors -->















.svg)