Guide to K8s Container Events: Tracking, Errors & Collection
Learn how to manage Kubernetes container events from tracking to errors. Use our essential guide to optimize Kubernetes container event management.

Running containers is the single most important thing that Kubernetes does. So, when your containers fail to start – or when they terminate unexpectedly – you want to know why.
Unfortunately, tracing container failures back to their root cause is not always easy.
Although Kubernetes keeps track of the various statuses that containers and Pods can operate in, it doesn't notify you explicitly about container failures. Plus, it sometimes takes some digging to figure out exactly what went wrong.
Fortunately, with the right approach, it’s possible to track container state information continuously in order to monitor what’s happening to your containers and Pods. But doing so requires a deep understanding of how Kubernetes tracks container and Pod status, how it reports error information and how you can collect all of the above in an efficient way.
Kubernetes container and Pod basics
There are three main types of Kubernetes infrastructure components to take into account:
- Nodes, which are the servers on which containers run. Monitoring nodes is a different affair from monitoring containers and Pods, so we're not going to touch on that here.
- Containers, which host the applications or microservices that you want to deploy on Kubernetes. Containers might also host software that provides auxiliary functionality, like monitoring agents, to complement the main application.
- Pods, each of which hosts one or more containers that perform an interrelated function. For example, a Pod could host one container to run a microservice, and another that provides configuration management for the microservice.
When you go about deploying an application in Kubernetes, you typically define that application as a Pod, then tell Kubernetes to run the Pod. Kubernetes will automatically decide which node should host the Pod (unless you specified a node manually) and prepare to run it. At this point, the Pod is in what Kubernetes calls the Pending phase. It's not running yet, but it's queued up for deployment.
Next, Kubernetes actually starts the Pod, placing it in the Running phase. This means the Pod itself is operational on a node and the containers inside it have been created. However, not all containers are fully started yet.
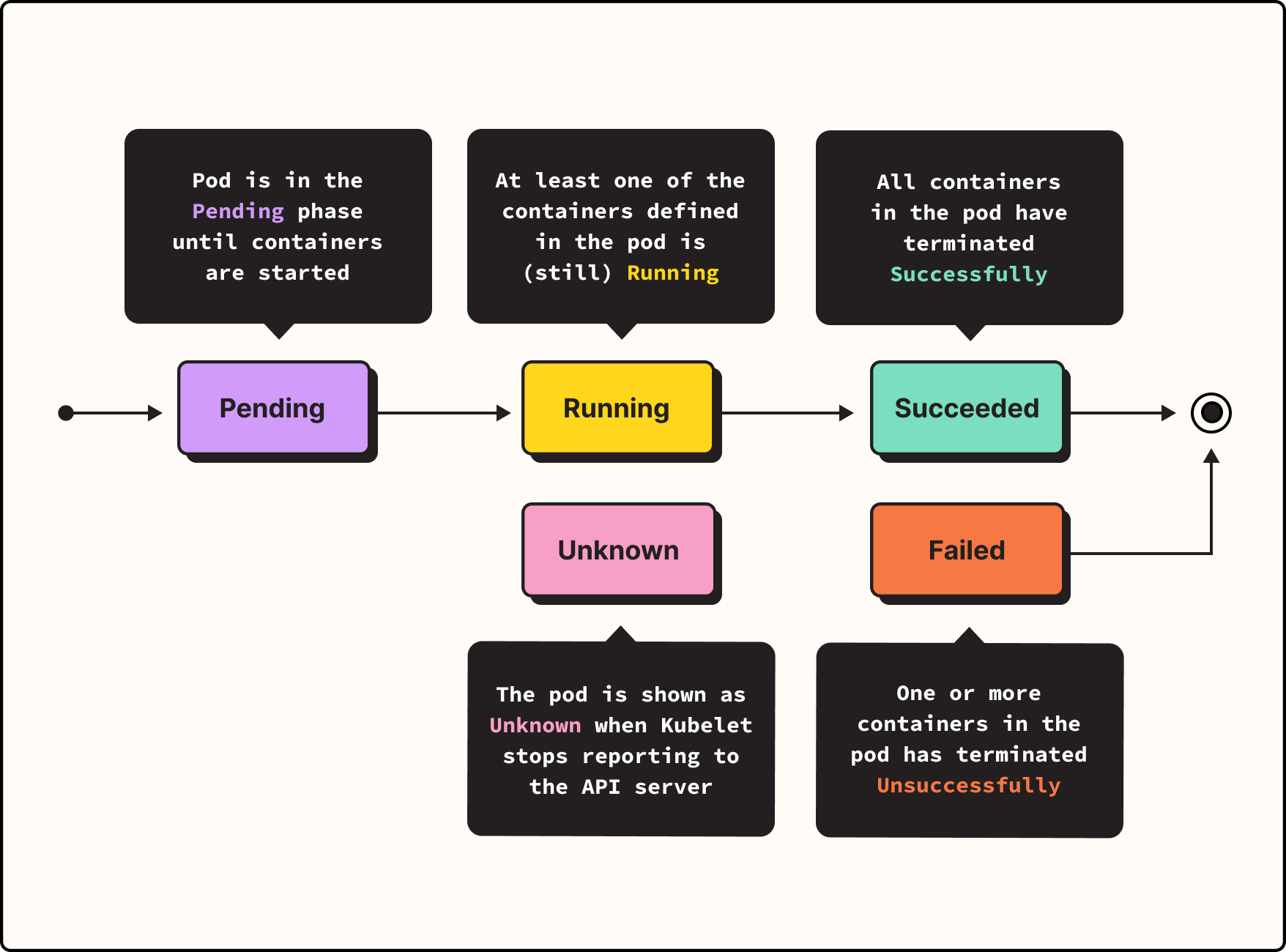
If all containers do start successfully, then the Pod enters the Succeeded phase. This is what you want to happen.
But if one or more containers inside the Pod terminates – which could happen due to problems with the container, problems with your Kubernetes configuration, or both – your Pod will be considered Failed. That's a bad thing, and you'll want to know why.
Pods can also be in the Unknown phase. This usually happens because of a problem communicating with the node. Although the containers in this case may have started correctly, Unknown also is not a condition you want, so you'll need to figure out what went wrong if you see an Unknown phase.
What happens when a Pod doesn't start
If your Pod reaches the Succeeded phase, things are looking good, and you can move on.
But what do you do if your Pod ends up in the Failed or Unknown phases? Well, you might first just wait a few minutes. If you set the restartPolicy spec in your Pod configuration to Always (which is the default) or OnFailure, then Kubernetes will attempt to restart the containers inside your Pod automatically. Sometimes, this does the trick. It may be the case that an unusual error (like I/O issues or a temporary network glitch) caused one of your containers to fail to start, but that things will work fine on the second attempt.
However, after a while (usually, five minutes, which is the maximum back-off period for Pod restart attempts), if your Pod continually ends up in the Failed phase, Kubernetes will stop trying to restart it. At that point, you'll want to look closer into Pod status and container states – which you can get through the Kubernetes API – to figure out what's going on.
Specifically, you'll want to check PodCondition, which gives you more detailed information about the Pod's status than you can get through the Pod phase data. In particular, PodCondition provides a type value with details about the status of containers inside the Pod.
You'll also want to take a look at the state of each container inside your Pod. The containers can be:
- Waiting, which means your container is still in the processing of trying to start.
- Running, which means the container is successfully running and has not exited with an error condition.
- Terminated, which means the container stopped running due to an error. You can use kubectl to check the reason, exit code and start and finish time for the terminated container.
A note on interpreting container exit codes
At this point, you may be thinking, "OK – so when my Pod fails, I just need to figure out which specific containers failed to start and get their exit codes to determine the root cause, right?"
Well, not necessarily. Although exit codes are certainly useful pieces of information to have, they don't always tell you everything you need to know.
Part of the reason why is that some of the exit codes (like exit code 134, which tells you the container aborted itself, but doesn't tell you why) don't provide very specific troubleshooting information.
But the other, bigger reason is that container exit codes can be derived either from application exit codes or from Kubernetes. For example, if a container exists with the 137 exit code, which in theory means it got a SIGKILL, it could actually be the case that the container stopped for an entirely different reason, and that the exit code came from the application. That's why you should always look at the “LastTerminationState.Terminated.Reason” property of the container to figure out what actually happened. You can't look at the exit codes alone.
Cutting through the noise of container termination
Since monitoring container exit codes is not accurate for measuring applicative issues, we wanted to develop a better approach to understanding container termination.
Specifically, we wanted to find a way to distinct application issues from infrastructure events. We wanted to trace terminations or restarts back to the applicative root causes, so we wanted to remove the noise of the following container events:
- An autoscaler scales down a Deployment/StatefulSet, causing a Pod and its containers to terminate.
- Updating Deployment image causes a container restart.
- Jobs have a definitive end.
- Init containers.
- Containers that ran to completion.
To do this, we started monitoring only the container restarts. This reduced the noise from the routine container exits and helped us focus on the applicative container issues.
A new way of looking at K8s container lifecycles - container restarts
Using this approach, we wanted to find a way to subscribe to structured container restart events with exit codes and restart reason. And we did it without installing any other third-party tool on our customers' clusters.
You might think that this would be a straightforward task, but it's not, as we'll explain.
The first challenge to overcome is deciding which data sources we can subscribe to. We have a few options:
1. cAdvisor - Analyzes resource usage and performance (https://github.com/google/cadvisor). cAdvisor does not export any metric regarding container restarts as far as we could find, so we used the following command to browse through the metrics:
2. kubelet - An agent that runs on each node in the cluster. It makes sure that containers are running in a Pod (see more). The kubelet API is undocumented, but while digging in the source code we couldn’t find a metric which satisfied us. There is a great post about kubelet API here
3. Kube-state-metrics - a simple service that listens to the Kubernetes API server and generates metrics about the state of the objects. We took a look at how it’s implemented their
metrics. The kube-state-metrics watches Pods using the cache.ListerWatcher interface from http://k8s.io/client-go/tools/cache package to watch containers and check if LastTerminationState exists. Unfortunately, though, those two metrics don’t provide the container exit code, only counters.
4. The Kubernetes API - The core of Kubernetes' control plane is the API server. It exposes an HTTP API that allows end users, different parts of your cluster, and external components to communicate with one another. The API also tracks how Kubernetes objects change over time by exposing diffs. This sounds promising!
Working with the k8s API:
So, let's take a closer look at the Kubernetes API, and more specifically on the k8s events:
“Event is a report of an event somewhere in the cluster. It generally denotes some state change in the system. Events have a limited retention time and triggers and messages may evolve with time. Event consumers should not rely on the timing of an event with a given Reason reflecting a consistent underlying trigger, or the continued existence of events with that Reason. Events should be treated as informative, best-effort, supplemental data.”
Again, though, no luck. There is no event for container restart. Plus the “Events should be treated as informative, best-effort, supplemental data” remark made us look for other sources which other k8s controllers rely on.
So the next obvious object to explore is Pod. As we noted above, the k8s Pod structure holds the spec of all its containers in the PodSpec, and the state of all its containers in the ContainerStatus struct.
Let’s look at the ContainerStatus struct:
The LastTerminationState holds the state of the last termination of the container. This field will be empty if the container has not terminated yet. This field will be overridden on each termination, and can hold only the last termination.
We can use the cache.ListWatch (just like kube-state-metrics) and watch for Pod update events. On each update we can compare the old and new Pods' ContainerStatus slices and check if the restartCounter has been increased. If so, we know that container has restarted!
But wait; there's more: If the container experienced a restart, we can collect all the interesting data regarding the container's last termination and create our own restart event!
ContainerStateTerminated struct:
Explore related posts
.jpg)
.jpg)
Sign up for Updates
Keep up with all things cloud-native observability.
We care about data. Check out our privacy policy.
Get started
with groundcover
Monitor everything, deploy in minutes.
See the platform in action
Book an on-demand demo with a customer engineer
100% visibility all the time.
Cover your entire Kubernetes stack instantly
with no code changes.
Troubleshoot like a pro.
Auto-detect issues across your entire cluster.
Reduce data & growth costs, dramatically.
See it all. Store what matters. Pay Accordingly.

Done!
Book a demo
Meet the groundcover team for a 30 minute live session
Explore how groundcover provides instant, out of the box insights across logs, traces, metrics, and more.
Get a walkthrough of the platform, pricing model, and real world use cases tailored to modern observability challenges.
Ask anything- our team will address your specific stack, scale, and deployment needs.








By submitting this form you agree to our friendly privacy policy.

.svg)