Microservices Architecture: Pitfalls & Implementation Tips
Explore microservices architecture, key challenges, and best practices. Learn how to build, scale, and manage microservices effectively.


Camper vans are like microservices architectures, in a way: they’re trendy, largely because they seem like the ticket to greater agility. Living out of a camper van might feel like the path to personal liberation, just as adopting a microservices architecture can seem like the best way to build flexible, scalable apps.
Microservices do deliver those benefits – at least sometimes. But other times, attempts to migrate to a microservices architecture don't work out as planned. They can crash and burn, just like Millenials' efforts to live the van life.
Now, we can't offer much perspective on whether or not a camper van is right for you (although the Internet has plenty of thoughts). What we can offer is an overview of the pros and cons of microservices – with an emphasis on the potential cons, because they're easy to overlook when you're getting excited about the potential of moving your monolithic apps to a microservices application architecture.
To be clear, we're not here to say that microservices are inherently bad, or that no one should use them. But we do think it's important to burst the hype bubble surrounding microservices. The reality of microservices architectures is that – although they truly have the potential to deliver lots of great benefits – many things can also go awry when you use microservices without the proper preparations.
What is microservices architecture?
A microservices architecture is an application development strategy that breaks application functionality into a suite of discrete services. Each service handles a specific task. When put together, the services deliver all of the business capabilities that the app requires to serve its intended purpose.
Microservices vs. monolithic architecture
We just gave you a basic description of what a microservices architecture entails. But in some ways, the easiest approach to understanding microservices is to think in terms of what they are not.
Here, we're talking about monolithic architecture, which is the opposite of microservices architecture. A monolithic architecture is a type of application design that builds all of an application's functionality into a single unit. The exact definition of monolithic architecture is hard to pin down because there are many ways to design a monolithic application. For example, most monoliths run as a single process, but in some cases, an app might start multiple processes at runtime. Monoliths also tend to have a single, unified codebase, but there's no law that says you can't separate their source code into multiple directories or files.
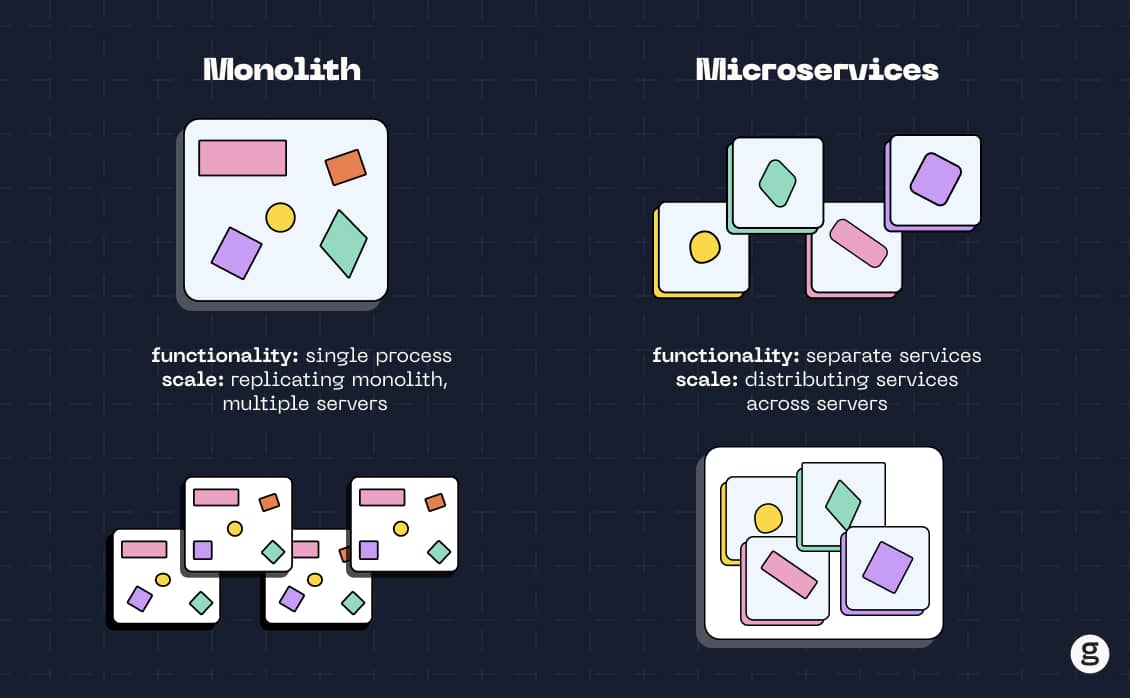
But setting aside subtle variations on the way a monolithic architecture can be implemented, it's fair to say that in most cases the key differences between microservices and monolithic apps boil down to:
- Tight vs loose coupling: In a monolith, all processes (if there is more than one) typically need to be running for the app to function at all, because the processes closely depend on each other – meaning they are "tightly coupled," to use a technical term. Microservices are "loosely coupled," which means they are independently deployable services that can operate separately from each other (although some application functionality might not be available if some services are down).
- Scalability: The independence of the service instances in a microservices architecture from other services makes microservices apps easier to scale because individual services can be scaled up or down individually. With a monolith, you'd need to scale the entire application – a more complicated and risk-prone operation.
- Host environment: The tight coupling of monolithic architectures means that most monolithic apps have to run on a single host. (It may be possible to run replicas of the app on other hosts, but that's different from using a truly distributed hosting environment.) In contrast, microservices designs make it possible to distribute an app across a cluster of servers, each of which hosts one or more discrete microservices.
- Complexity: Because microservices apps contain more moving pieces, they require more effort to design, implement, deploy, and manage. Indeed, one of the biggest arguments in favor of monolithic architectures is that they are just simpler, and sometimes, the benefits of simplicity outweigh the benefits that microservices deliver.
Microservices vs. SOA
It's worth noting, by the way, that there is a middle ground between microservices and monoliths. It's called Service Oriented Architecture (SOA). SOA means breaking a monolithic application into a relatively small set of services – such as one to handle the frontend and one for the backend.
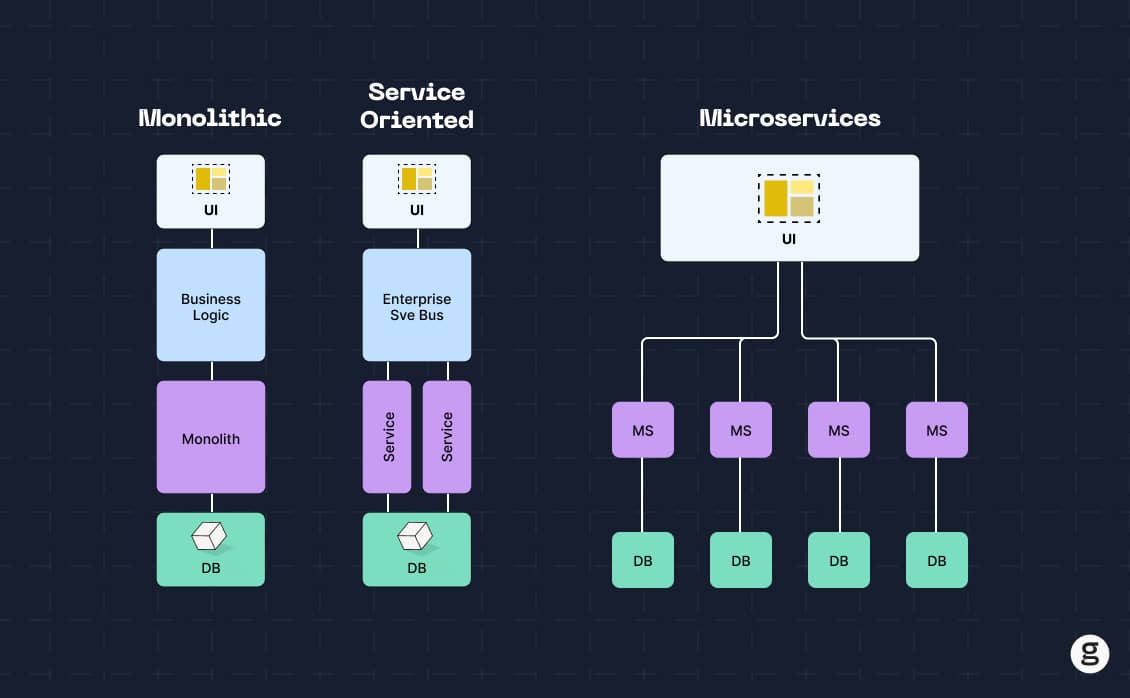
In the 2000s, SOA was a popular way of making monolithic apps a bit more flexible. But the consensus among developers and DevOps engineers today is that SOA tends to give you the worst of both worlds: You get added complexity, but without most of the scalability and efficiency benefits of a real microservices architecture. So, today, most teams opt either for microservices or for monoliths - SOA is no longer a widely used design strategy.
What to know about microservices observability
The main reason why observing microservices can be hard is that this “fatter technology stack” demands much more attention and a more complex integration for R&D teams. Moreover, it introduces the following issues:
- Root causes are not always obvious within distributed microservices environments.
- Each microservice typically generates its own logs and metrics, so there is more data to collect and analyze in order to observe the application state.
That said, one way to simplify microservices observability is to take advantage of the fact that microservices are API-driven by observing API performance in addition to relying on metrics, logs, and traces from your microservices themselves. Because API transactions involve exchanges between microservices, tracing API calls is a great way not just to identify performance issues, but also to determine which microservices did what during a problematic transaction – and which ones are therefore likely to be the root cause of problems.
The fact that focusing on observing APIs frees you from having to instrument observability within each microservice is icing on the cake. You can collect most of the data you need to observe your app from API transactions, rather than having to run agents alongside each microservice or add code to each one to expose metrics and logs directly.
Key characteristics of a microservices architecture
Now that we've covered the basics of what microservices mean and what makes them different from monoliths, let's dive deeper into what a microservices architecture entails.
This is a bit tricky because, as Martin Fowler and James Lewis note in one of the most influential essays on microservices, there is "no precise definition" of a microservices architecture. In other words, there is no one right way to design a microservices app. Nor are there specific tools, programming languages, or deployment technologies that you must strictly use to implement a microservices app. Instead, you should think of microservices as a high-level style or approach to app development more than a rigid recipe for designing applications.
That said, in practice, most microservices design patterns involve the following characteristics:
- Each microservice handles a discrete facet of application functionality: There are no hard-and-fast rules about how to divvy up functionality, but you might, for instance, devote one microservice to handling authentication, and another to interfacing with a database that your app needs to access.
- Codebases are broken into discrete units: Developers maintain the code for each microservice separately.
- Each microservice is deployed separately: Running each microservice in its own container is the most common way of achieving isolation between microservices during runtime, but it's not the only viable approach. You could also use serverless containers, or even just deploy each microservice as a separate, non-containerized process.
You can redeploy and update services independently of each other: If one microservice stops running, the others will remain operational (although the functionality provided by the non-running microservice will become unavailable).
Microservices architecture common use cases
You can use a microservices architecture for almost any type of app or use case. But to provide a sense of what makes microservices useful in the real world, here's a look at scenarios where microservices can offer particular benefits.
Data processing
Data processing workloads often require moving and analyzing large volumes of information. Microservices can help here by delegating these tasks to individual services, which can scale independently of others.
In other words, rather than having to scale your entire monolithic app in order to accommodate more data, you can scale up just the specific services that perform work like data ingestion, transformation, and analytics. You don't need to waste resources duplicating other parts of the app (like the frontend) that don't have to scale to support changing data processing workloads.
Media content
Applications that manage media content are similar to data processing apps in that certain parts of the apps may need to deal with large volumes of data, while others don't. The ability to manage different parts of the application separately is an advantage of microservices in this context.
For instance, consider a web app that allows users to upload video files, which need to be reformatted after being uploaded – a compute-intensive task. With a microservices architecture, you could devote more compute resources to the microservice responsible for video processing whenever a user uploads a video. Meanwhile, the rest of your app's resource utilization would not change. This is a more efficient approach to resource management than you could achieve using a monolith, where you'd have to allocate resources to the entire application.
Transactions
Applications that need to support high rates of transactions are good candidates for a microservices architecture. Here again, the main reason why is that microservices make it possible to delegate application functionality to discrete pieces, and then manage each one independently.
That way, you can scale each microservice based on the number of transactions it is processing at a given point in time. You might have one microservice that handles order history lookup requests, for example, while another processes payments. Since the request rate for each type of transaction is likely to be independent of the other, the ability to scale each function separately is beneficial.
Website migration
If you currently have a website that you’re considering modernizing or migrating, you might choose to convert it to a microservices architecture.
The exact way that you do that would depend on factors like how the site is currently designed and which programming language or framework it uses. But in general, a shift to microservices would likely entail breaking the website's functionality into discrete services. For instance, one service might serve text while another delivers images and a third serves videos.
The advantage of microservices in this case is that they would make the website architecture more granular. If you wanted to change the way you process text before serving it to users, for instance, you could update just the microservice responsible for text, without changing how you deliver other types of content.
Real life microservices architecture examples
Still not convinced of the value of microservices architectures? Consider the following examples of how big-name companies have put microservices to use.
Amazon
Amazon traces its origins to a humble online book store launched in the mid-1990s, back when PHP was a cutting-edge programming language. Suffice it to say that at the time, no one was thinking about building massively scalable, high-performing Web apps using microservices.
But as Amazon grew, it realized that it needed a more flexible architecture for its site, which at the time operated as a monolithic app. In addition to performance and scalability challenges, Amazon's original design made it difficult to introduce new features to the site and stick to development timelines, since developers were working with a massive, monolithic codebase.
So, as the retailer grew, it broke its development teams and processes into smaller units – giving rise to famous concepts like the "two-pizza team" (meaning the idea that each individual team of developers should be small enough that two pizzas would suffice for feeding them all a meal). Along the way, its software platform evolved into a more modular form, too.
Ultimately, Amazon's success in migrating to a microservices-oriented approach helped not just to improve the performance and scalability of its retail site. It also helped Amazon launch a public cloud computing platform – which also required a highly agile, scalable design – and become the world's leading cloud service provider by market share.
Netflix
Like Amazon, Netflix originated in the 1990s and originally did not require a particularly sophisticated Web platform. That's because, at first, Netflix's business model centered on shipping DVDs through the mail.
But starting in the 2000s, Netflix began transforming itself into a streaming video provider. To do this well, the company needed to build a platform that was not just capable of scaling to support millions of simultaneous video streams, but that also delivered ultra-low latency.
Hence the company's decision to implement over 100 individual microservices to build out its technically complex streaming service. Combined with other optimizations, like the use of Content Delivery Networks (CDNs) to improve reliability and performance for video streams, microservices played a key role in helping Netflix build a platform that is easy to take for granted today, but which was an amazing feat when it was first conceived decades ago.
Uber
Uber, which launched in 2009, started building its platform at a time when microservices were already coming into vogue. Nonetheless, the company initially developed a monolithic app based on Python.
Unsurprisingly, Uber's monolith didn't scale well. As its customer base and engineering teams grew, it knew it needed a more flexible architecture – which is why Uber today relies on 4,500 discrete microservices.
That transformation entailed more than just breaking out Uber's code base and assigning different services to different engineering teams. The company also innovated ways of centralizing and standardizing its deployment processes, ensuring that it can smoothly complete as many as 100,000 deployments every week.
Etsy
Etsy's microservices journey is a story of slow but steady change. Seeking to improve the performance of its retail site, the company first decomposed its architecture so that a series of meta endpoints would serve website content.
However, a lack of concurrency optimizations made it difficult to achieve the best possible performance under this approach. So, Etsy engineers redesigned their strategy for handling API calls, which improved concurrency and allowed Etsy's Web and mobile apps to operate with true efficiency at scale.
Microservices are for everyone – not just big companies
Lest we leave you with the impression that only organizations with the budget and engineering chops of companies like Amazon and Netflix are capable of pulling off microservices development, let's make clear that you don't need to be a large, deep-pocketed tech company to take advantage of microservices. Anyone can do it.
After all, implementing microservices really just boils down to designing applications so that they operate in a modular way, as well as ensuring that each of the modular services can integrate with each other. It doesn't require any special tools, programming languages, or specialized software engineering expertise. Large tech companies like Amazon and Netflix were among the first to dive head-first into microservices, but today, you'll find microservices architectures in use at organizations of all types and sizes.
The benefits of using a microservices architecture
At a high level, the benefits of adopting microservices are that they allow teams to break complex codebases and applications into smaller units, which are easier to manage and easier to deploy. In the cloud, microservices can help to consume cloud resources more efficiently, as well as to improve the reliability of cloud apps.
But to go deeper, here's a more detailed list of the benefits of using a microservices architecture:
- Fast and easy deployment: Since microservices can typically be deployed independently of each other, it's faster and easier to deploy a microservices app – and to make continuous updates to it in order to implement new business capabilities – than it is to deploy and update a monolith. Being able to deploy microservices in containers, which helps to provide parity between dev and prod environments, also simplifies things from a software delivery perspective.
- Scalability: By a similar token, you can scale microservices applications quickly and – if desired – granularly. You can quickly deploy additional instances of the microservices that your app needs to handle an uptick in requests, and you can shut the instances down when they're no longer needed to save money.
- Code maintainability: By breaking large codebases into smaller pieces, microservices make developers' lives easier. It's simpler to implement new features or track down and fix bugs when you can work within the code of just one microservice, as opposed to having to worry about an entire application's codebase.
- Fault tolerance: The fact that microservices usually operate independently of each other means that they have high fault tolerance. As we’ve explained above, if one microservice fails, the others keep working, increasing the reliability of your app.
- Experimentation: In some respects, microservices allow developers to experiment more while reducing risk. If you want to add a new feature to your app, you could deploy it as a separate microservice to test it out. If it causes issues, you could simply remove it, without having to redeploy the entire app.
These are the main reasons why software architects, developers, DevOps engineers, SREs, and everyone else who cares about fast, reliable applications are into microservices these days.
Challenges of a microservices architecture
We said it before, and we'll say it again: Although microservices can deliver a lot of benefits, they also have the potential to introduce a lot of problems – especially for teams that fail to plan ahead to mitigate those problems.
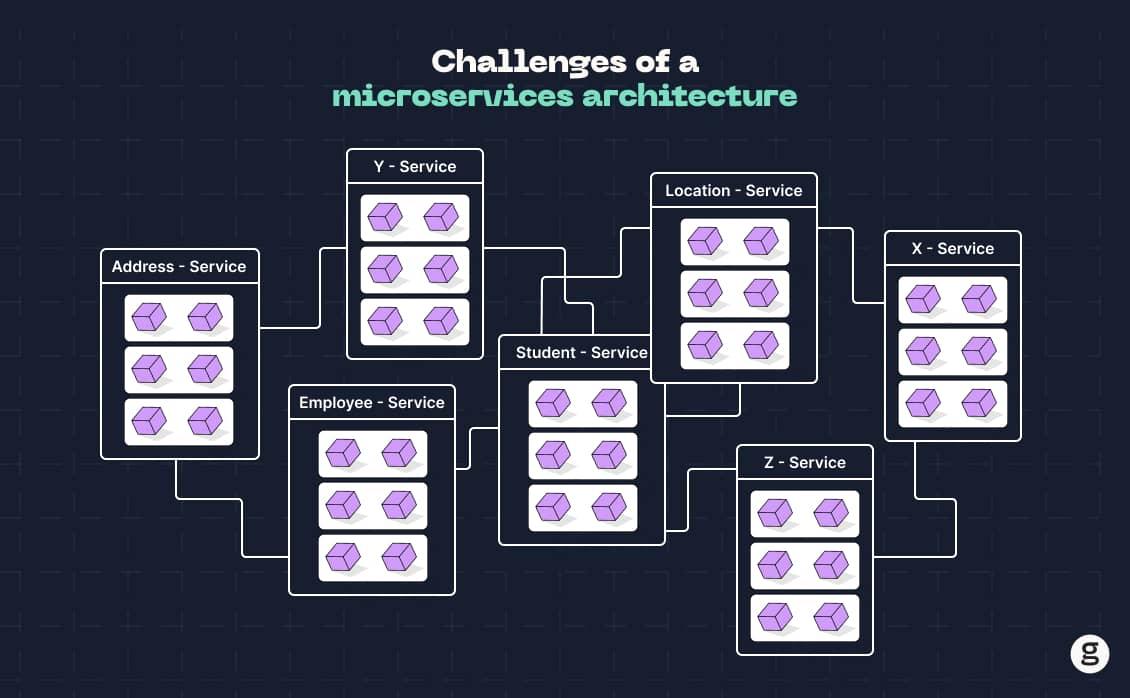
The main challenges you're likely to run into if you adopt a microservices architecture include:
- Interprocess communication: Although microservices can run independently, they need to talk to each other and share data. That requires a complex inter-process communication framework within the application – typically, one driven by APIs. Implementing interprocess communication increases developer effort. Interprocess communication also adds to the number of things that could go wrong with an app, and it can make it challenging to maintain data consistency across discrete microservices.
- Fatter technology stack: Microservices require more resources to run in the sense that a microservices app typically depends on an orchestrator, an API gateway or service mesh, and a cluster of servers. This means you end up with a "fatter" technology stack than you'd use for the typical monolith, which you can run on just a single server, without needing an orchestration layer or other services to help manage your distributed app.
- Testing and debugging: Getting to the root cause of performance issues tends to be tricky when you use a microservices architecture because it's not always readily obvious which microservice is causing a problem. For instance, an error in your app's login process may be triggered not by the microservice that handles authentication, but by some backend microservice that the authentication process depends on.
- Deployment complexity: Because each microservice needs to be deployed separately, there is more effort required to deploy microservice applications. You'll typically need to set up a different CI/CD pipeline and release automation tooling for each microservice, which is a lot more effort than having to manage just one deployment for a monolithic application.
Microservices planning best practices
Given the many ways that microservices designs can be implemented, there are no hard and fast rules about how best to work with microservices. But a general guide includes the following tips:
- Organize your microservices architecture strategically: Think carefully about how many microservices you implement and which functionality each one addresses. Having too many microservices – or too much overlap between their functionality – can overwhelm you with complexity when it comes to tasks like microservices monitoring. On the other hand, having too few will deprive you of the benefits that microservices are supposed to deliver.
- Iterate and test: In addition to planning your microservices architecture carefully, experiment with different iterations to see how effective they are. You don't need to have written your entire codebase to run these tests - you can use techniques like mocking to evaluate how different architectural patterns impact microservice behavior.
- Choose the right data storage: You don't need to adopt any specific type of storage system (such as object storage or file system storage) to use microservices, but factors like how fast you can read and write from storage and how scalable the storage is will impact application performance. In addition, storage costs can vary depending on which type of storage you choose. Assess the different options and cost-benefit tradeoffs before committing to specific types of microservices storage.
- Choose the right hosting solution: Hosting environments for microservices apps can vary widely, too. Compare the benefits of drawbacks of different options, such as on-prem vs. cloud-based hosting, deploying microservices as containers vs. serverless functions, and deploying microservices on a single server vs. using a cluster of distributed nodes.
- Have a maintenance plan: Your microservices will probably need to evolve over time as your developers fix bugs and add new features. Have a plan for redeploying new versions of the microservices in a way that minimizes disruption to the overall application and users. For example, you might consider using a blue/green deployment strategy, which helps to switch seamlessly from one version of an application to another version that undergoes validation before becoming the "live" version.
How to get started with a microservices architecture step-by-stepAgain, there are many ways to go about implementing a microservices architecture, and the steps you take will depend on factors like what your microservices use case is and the type of programming languages you are leveraging.
That said, the basic process for implementing microservices typically boils down to these steps.
1. Decide how to decompose your application
First, you must determine how you'll break your monolith into microservices. Which services will you implement, and how will they map onto application functionality?
The most common approach to decomposing an app is to create a microservice for each key feature. For example, in a retail Web app, you might have one microservice that handles product search, another that operates a shopping cart, another that enables checkout, and so on.
Another popular strategy is to decompose the app based on your engineering teams – in other words, each team will become responsible for managing a different microservice, which may or may not correspond with a distinct application feature.
Other approaches are available, too. Amazon offers a useful overview of monolith decomposition strategies.
2. Build the microservices
The next step is implementing the microservices by breaking apart your monolithic codebase into a set of smaller units, one for each microservice.
The complexity of this task will vary depending on what your monolithic codebase looks like and which microservices you've chosen to build. If your codebase is organized based on features, and you are also implementing microservices that correspond with those features, building the microservices is likely to be relatively straightforward. In that case, you can effectively lift-and-shift much of the original code to build microservices.
Expect it to be much harder if the codebase you start with bears little resemblance to the microservices you want to create – in which case you'll likely need to do a lot of work to rewrite the microservices from scratch.
3. Implement service integrations
For your microservices to function as a cohesive app, they need a way of communicating with each other. That means you'll need to implement a service discovery solution that allows the microservices to identify each other, and then exchange data as needed.
You can do this by writing logic for these tasks directly into the microservices. But you may find it easier to outsource some of the work to a service mesh, an independent infrastructure layer that assists with service discovery microservices communication.
4. Plan an observability strategy
In addition to determining how your services communicate, you'll need a solution for observing them – which is important, of course, because observability is the only way to guarantee you know what's happening in a complex microservices app and can discover performance issues before they impact customers.
Service meshes can help here by providing some observability features. However, we tend to think that conventional service meshes are not the ideal observability solution for microservices apps, and that you'll be better suited by the hyper-efficient, highly secure observability solution known as eBPF.
5. Test your app
We'd be remiss if we didn't remind you to test your microservices in a dev/test environment before deploying them to production – so, once you've written and built the services and decided how you'll handle service integration, spin up a test environment to validate that the app actually functions as expected.
6. Deploy to production
With your app ready to go, the final step in getting started with microservices is deploying them to a production environment.
The exact process here will depend on how you've chosen to run your microservices. But matters should be relatively straightforward if you use containers to host each microservice, which is what you'd typically do if you opt for a modern, cloud native approach. In that case, you can simply spin up a Kubernetes cluster, configure it as needed to ensure proper network connectivity and storage for your microservices, then launch your containers as sets of Pods.
The eBPF approach to microservices architectures and observability
The bottom line: We can't promise that adopting a microservices architecture will be a pain-free experience. Tasks like having to manage multiple other services and deal with more complex technology stacks are real challenges. When it comes to observability, however, the potential pitfalls surrounding microservices’ can be conquered.
Thanks to tools like eBPF, there are virtually no limits on the amount of information we can collect about microservices state and performance. eBPF opens up new ways to observe an API-centric architecture which means that you can observe any app – whether it's a monolith or a set of microservices – with zero instrumentation and without compromising on the depth or granularity of data; making those pesky aforementioned issues a walk in the park for you and your R&D team.















.svg)

