Microservices Logging: Best Practices, Importance & Challenges
Explore Microservices Logging: Learn About Its Importance, Key Challenges, and Best Practices for Mastering Observability


Last updated: July 4, 2026
The issue is this - the more microservices you have running in a Kubernetes cluster, the more challenges you'll face in the realm of microservices logging and management. Although microservices don't change the fundamentals of how admins should approach logging, they do increase the complexity of logging routines. That doesn't mean that you can't handle microservices logging effectively. But it does mean you should evolve your logging strategy when you migrate from monoliths to microservices.
To show you how, this article walks through everything a Kubernetes admin needs to know about microservices logging, including how it's different from monolithic logging, which special logging challenges you'll encounter when working with microservices and best practices for keeping microservices logging efficient and effective.
What are Microservice Logging and Microservices?
A microservices architecture is a type of application architecture that breaks an app's functionality into a set of multiple services. This is the opposite of what's known as a monolithic architecture, in which the entire application runs as a single service.
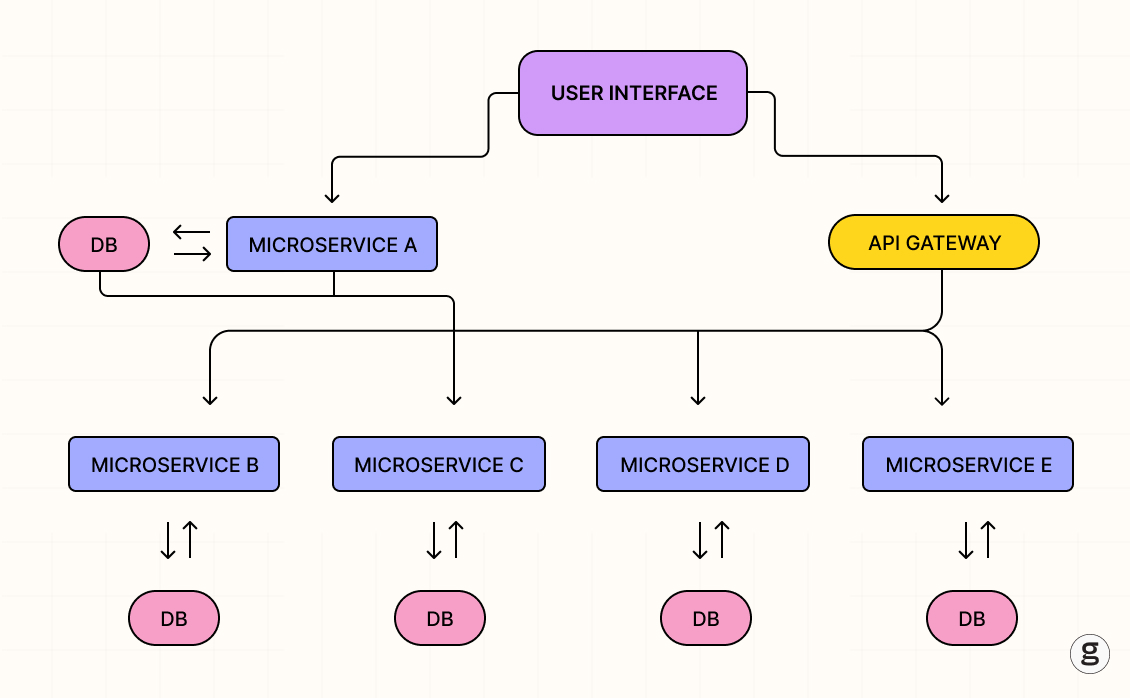
The microservices concept has been around in one form or another for decades – you can find shades of it in the microkernel vogue of the 1980s, for example, which broke operating system kernels into multiple services, and in the Service Oriented Architecture (SOA) trend of the 2000s. However, it wasn't until the widespread adoption of containers and Kubernetes starting about ten years ago that microservices really came into their own. Since containers make it easy to deploy each microservice separately (because you can run each in its own container), and Kubernetes makes it easy to orchestrate a group of microservices running in separate containers, microservices go hand-in-hand with modern, cloud-native technology.
Importance of microservices logging
Whether you run a monolith or a microservices app, logging is essential for keeping track of what the app is doing, identifying events (like dropped requests or I/O errors) that could signal a problem, and helping you troubleshoot issues when failures occur.
In fact, you can argue that logging is even more important when you're working with microservices because microservices based applications increase complexity and generate more events across different services. In that sense, there is more data to log, and more information to sift through to ensure that your microservices app is operating as required.
That's why it's critical to ensure that you collect and analyze logs for every service in a microservices application.
Monolith vs. microservices logging
The fundamentals of logging are the same whether you're working with a monolith or with microservices. In both cases, logging involves generating log data, collecting it and feeding it into an analytics tool where you can make sense of the logs. Practices like log rotation, log aggregation and log retention also apply for any type of app. A monolithic application is often simpler to observe because logs come from one runtime.
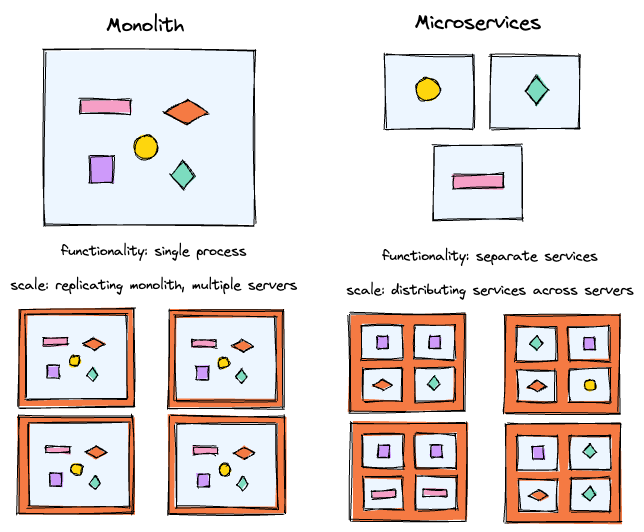
That said, there are some key differences in how logging works for monolith vs. microservices apps:
- Number of logs: The biggest difference is that with microservices, each microservice will typically produce its own log file. In a monolith, one service effectively covers the entire app, so you generally have just one log file.
- Log correlation: Having more logs makes it more important to be able to correlate log data between logs when you're working with microservices. Correlation means understanding how log messages in different logs relate to each other so you can more easily identify the root cause of a problem.
- Ephemeral logs: Because it's common (although not required) to run microservices in containers, and because containers can't store log data persistently, microservices logs tend to be ephemeral. This means you have to collect them when the container is running, or find a way to write them to persistent storage before the container shuts down. Otherwise, they will be lost forever.
- Distributed architecture: Typically, microservices apps hosted on Kubernetes will be deployed across a cluster of nodes. This means that you need to be able to collect logs from multiple servers, often without knowing ahead of time which node will end up hosting which microservice at any given time, while also following interactions with other services. Unlike logging for monoliths, managing logs for microservices is more complicated than simply pulling all log file data out of a directory like /var/log from a single server.
Challenges in microservices logging
In light of the preceding section, you have a sense of what makes microservices logging challenging. It all boils down to the fact that microservices significantly increase the complexity of logging architectures and workflows. Not only do you have a larger total number of logs to work with, but you also must work harder to correlate log data effectively between logs.
After all, analyzing individual microservices logs in isolation is not very useful if you can't correlate them in ways that make clear how an event in one microservice (such as a failed authentication attempt in a microservice that handles authentication) correlates with another event (like a dropped request by a frontend microservice). When requests cross service boundaries, isolated records make debugging errors harder, so each entry needs enough context to show how related events connect across services.
These logging challenges don't mean you should abandon microservices. On the contrary, the benefits that microservices provide – like more flexible and scalable application architectures – can far outweigh the management drawbacks. But for this to be true, you need to have an effective logging strategy in places that provides the visibility you need across all of your microservices log files and captures system errors clearly.
The value of a centralized logging service
The best way to tame the complexity of microservice logging is to centralize your workflows as much as possible with a centralized logging system. This means that instead of collecting logs from each microservice with a separate tool or service, you deploy a logging system for your cluster and configure it to collect data from all the microservices you need to monitor in a single location for easier access, analysis, and log management.
How to set up a centralized logging service
There are different ways to implement a centralized logging service, each with varying considerations:
- Using sidecar containers: One approach is to run a logging agent as a sidecar container within each Pod that you deploy, then have the sidecars connect to your centralized logging app. The downside here is that sidecar containers increase overhead.
- Using application logic: Another approach is to implement logic directly within each microservice by using a logging framework that tells the microservice how to connect to your centralized logging service. Many teams also forward application logs from the service to an http endpoint exposed by the central collector. However, this is very challenging unless you have just a handful of microservices to work with, because you have to instrument the logging code in each microservice and update it whenever your logging configuration changes.
- Using eBPF: A third strategy – and the one that groundcover uses – is to leverage the eBPF framework to collect log file data for each workload via the Linux servers that host them. This is more efficient than using sidecar containers, it eliminates the need to instrument logging code in each microservice itself, and it avoids depending on each service’s own log files.
Microservice logging best practices
Centralizing logging is the first step in working effectively with microservices logs, but there are additional best practices to follow to make microservices logging as efficient and effective as possible.
Use a correlation ID
Correlation IDs are unique identifiers that you can assign to events in logs. By assigning the same IDs to events handled by different microservices, you can more easily track how various microservices handle a given event, and the same ID should appear in the log entries created by each service.
For example, when a user submits a request, the frontend microservice that receives it would log the request using a unique ID before handing it off to backend services. Then, the backend services would use the same ID when recording how they process the request. This makes it simple for admins to track the request flow within the distributed microservices app, and searching combined logs by the correlation ID lets teams trace the request across different services.
Keep logs consistent
There is nothing stopping you from having the log file for each microservice record different types of events, or write log data in different ways, but it's better to keep a consistent json format across services. However, the more consistent you make logging for each microservice, the easier it will be to collect and analyze logs. It's a best practice to establish how you'll record log events early in the microservice development process, then implement each microservice in ways that adhere consistently to your plan, which is easier when teams standardize system logs alongside business events.
Log aggregation
Sometimes, log data is so similar that it makes sense to perform log aggregation, which means consolidating multiple log files into one log. Doing so can simplify log collection and speed analytics because it leaves you with fewer log files to work with.
Just be sure, however, that following log aggregation, your logs retain the information you'll need to determine which events correlate with which microservice. In other words, don't implement log aggregation in ways that merge events generated by distinct microservices while leaving you with no means of determining which microservice originally recorded which event.
Add contextual data in logs
The more data your logs record to add context around a given event, the easier it is to understand or troubleshoot it. It's best to adopt the "more is more" (rather than "less is more") approach when configuring microservices logs, so long as you're not recording redundant information, because those fields provide important context for analysis and troubleshooting. Wherever possible, be sure that log events include details like which node an event occurred on, when a request was first received, when processing for the request ended, and enough information to pinpoint what happened when an error occurred.
Use structured logging
Although you can manipulate log structures relatively easily, it's best to structure your logs by default so they produce machine-readable log entries, often in JSON format, and make it easy to correlate multiple microservices logs without having to change the way log data is structured. The simplest way to do this is to implement a structured logging strategy that organizes events chronologically based on timestamps, which also helps monitoring tools filter and analyze structured records more easily. But depending on which types of data you're logging, you might instead choose to organize them around types of requests, for example.
Use different log levels
Log levels indicate how important an event is. By configuring log levels for different events, you make it easier for your analytics tools and admins to identify high-priority events. For example, a log entry that records the reception of a user request might receive an "INFO" log level because it's contextual data that doesn't indicate a problem, while error logs for a dropped request — which is something that may require action on the part of admins — would be recorded at the "ERROR" level.
Avoiding direct logging of sensitive data
It's a best practice to ensure that your logs don't include sensitive data like personally identifiable information or passwords. Instead, mask or obfuscate that data by, for example, encrypting password data before storing it in a log. In cases where logging sensitive information is absolutely unavoidable, encrypt the log file itself and store it in a secure location.
Use centralized log storage
To simplify microservices logging, consider not just collecting logs using a central service but also storing them all in a central repository instead of sending them to separate destinations. For example, you can set up a storage volume that handles the logs for all microservices in a given app, or even all logs from across an entire namespace or cluster, which also improves log management for hybrid environments.
Keeping logs in one place makes it easier to ensure you have proper disk space available to support your log files as they grow. It also allows you to back up all of your log files from a single place, and to enforce a consistent set of security rules across them.
Minimize logging load
Log file collection, log aggregation and analytics can consume significant amounts of CPU and memory. In Kubernetes clusters with limited resources, this means that logging activity could cause insufficient resources to become available to your actual workloads, leading to performance degradations.
Teams sometimes run performance tests when choosing or tuning their logging approach to measure this overhead in practice.
To avoid this risk, be sure to plan your logging strategy based on the resource constraints of your environment. For example, as we mentioned above, relying on techniques like eBPF-based logging can help reduce the overhead associated with logging, as compared to more resource-intensive approaches like using sidecar containers to host logging agents.
Achieving observability through logs
It's important to note that while logs are one key source of visibility into microservices apps, they are only one element of observability. You'll also need metrics and distributed tracing to gain the fullest possible context on what is happening inside your application.

This means that, in addition to collecting logs, you should also be tracking resource utilization metrics for each microservices and using tracing to follow requests across multiple services and measure latency. Then, you should correlate all of this data to identify and troubleshoot problems.
Read more about Microservices Observability.
Microservices logging with groundcover
Groundcover helps you collect the logs, traces, metrics and any other data you need to establish observability into your apps. With groundcover, you can monitor all of the microservices in your environment using a centralized tool.
And thanks to groundcover's use of eBPF to collect data, you get a hyper-efficient, hyper-secure solution that allows you to optimize observability without paying a high price in resource overhead.
Gain complete observability
Microservices help to solve many problems, like the need to break complex apps into more manageable pieces. But they also create some problems, not least of which is logging.
Fortunately, microservice logging is a challenge that becomes easy to conquer once you have the right tools and techniques in place. In microservices application environments, where stack traces alone rarely show the full request path, complete observability comes from centralized logging plus traces and metrics in a single workflow.















.svg)