gRPC Load Balancing: Architectures, Examples & Best Practices



While gRPC is a powerful framework for enabling connections between services, when you have multiple requests flowing between multiple gRPC server instances, optimizing performance requires a way to distribute those requests efficiently. This is where gRPC load balancing comes in. By spreading client calls across gRPC servers, gRPC load balancing plays a critical role in preventing bottlenecks, using resources efficiently, and minimizing latency.
Read on for details as we unpack how gRPC load balancing works, the different types of gRPC load-balancing architectures, common issues that occur in the context of gRPC load balancing, and best practices for distributing gRPC calls efficiently and reliably.
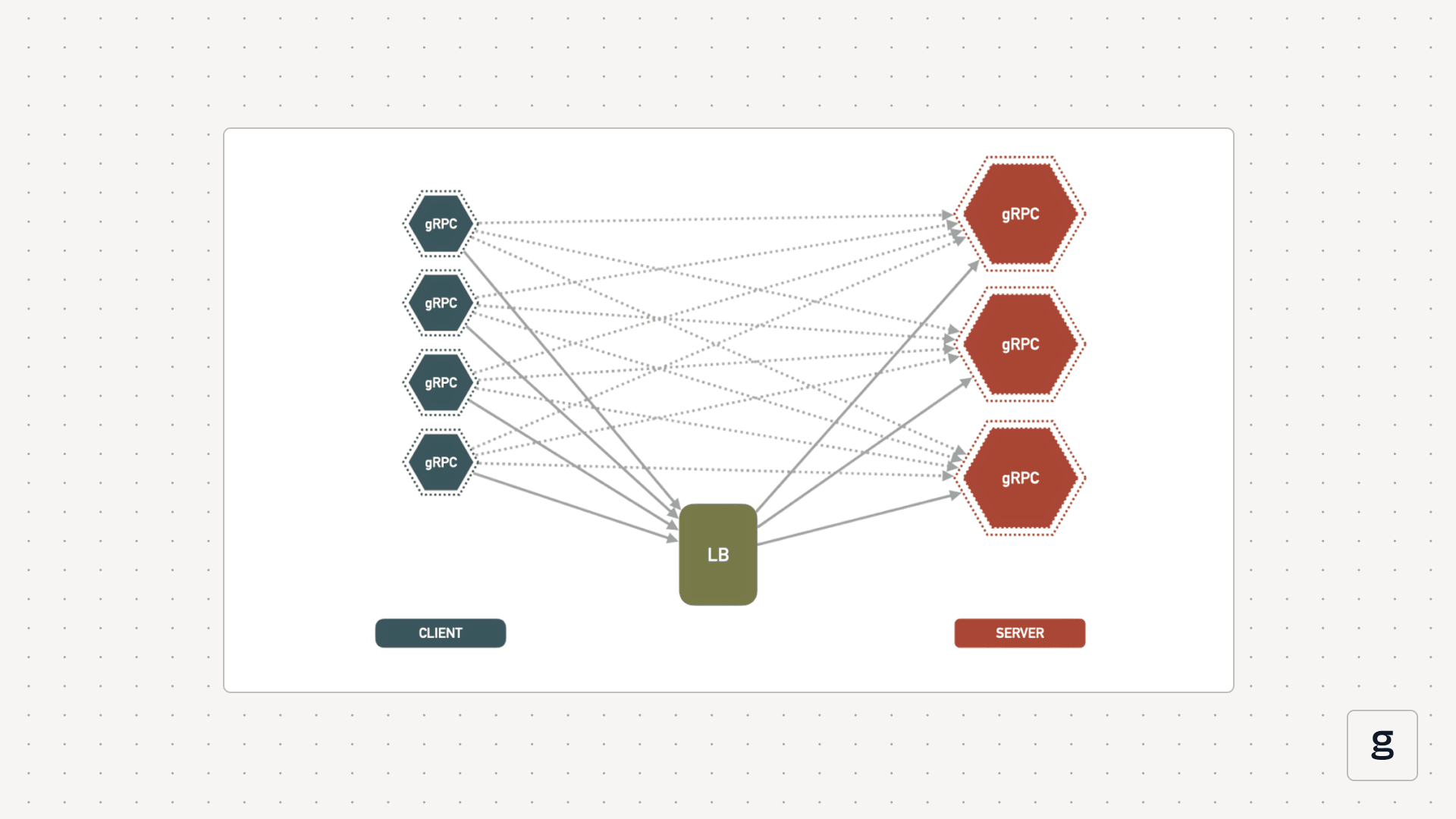
What is gRPC load balancing?
gRPC load balancing is the practice of distributing calls from gRPC clients across multiple gRPC server instances.
To understand fully what that means, it helps to understand how gRPC works. gRPC is a framework for enabling service-to-service communication. A service that sends a request to another service is a client. The responding service is a server. It’s possible to implement multiple gRPC server instances for the same service, and doing so helps to ensure that services don’t become overwhelmed with requests.
However, simply adding gRPC server instances doesn’t guarantee that a service will handle requests effectively. There is a risk that some of the server instances will sit idle or underutilized, while others are flooded with client calls. And gRPC itself includes no built-in capabilities for distributing requests evenly or utilizing multiple server instances efficiently.
gRPC load balancing solves this problem. It provides a way to distribute client calls across backend servers such that server resources are used efficiently. The end-result is better performance and a lower risk of service-to-service communication failures.
gRPC load balancing works by implementing logic either with the client or the server to distribute calls efficiently.
Why traditional load balancers fail for gRPC traffic
At this point, you may be thinking: I already use a load balancer to manage network traffic, so why would I also need a gRPC load balancer?
The answer has to do with the way gRPC connections work. gRPC uses HTTP/2, which makes it possible to establish a single connection and multiplex calls across it. This is different from HTTP/1.1, the protocol used by many other communications frameworks. HTTP/1.1 loads resources sequentially. gRPC’s multiplexing technique is more efficient overall because it enables parallel loading and avoids the bottlenecks that can arise if resources are loaded one-by-one.
However, gRPC multiplexing also means that load balancers that can only manage traffic on a per-connection basis (which is how most traditional network load balancers work) don’t work well for routing gRPC calls. This is because, to a traditional load balancer, a stream of gRPC calls appears to be just a single connection request, since they all flow over the same connection. A traditional load balancer would therefore think there is only one connection to distribute, and it would assign it to just one server instance, making it impossible to use a multi-server setup effectively.
Per-call vs. per-connection load balancing in gRPC
To solve this problem, gRPC load balancing works on a per-call basis rather than a per-connection basis.
This means that a gRPC load balancer decides which server instance should handle each individual client call. Different server instances could respond to calls from the same client. This type of approach is called L7 load balancing because it focuses on routing traffic at Layer 7, as defined in the Open Systems Interconnection (OSI) model (OSI is a widely used conceptual networking framework that network architects use to make sense of how data moves within computer networks).
Again, this is distinct from traditional network load balancers (or more specifically, L4 load balancers, which operate at Layer 4 of the OSI networking model), which operate on a per-connection basis and therefore can’t distribute gRPC calls efficiently when multiple calls flow over a single connection.
gRPC load balancing architectures
As we mentioned, there are two basic ways to go about implementing gRPC load balancing: You can use a client-side or a server-side architecture.
Server-side
In a server-side gRPC load-balancing architecture, a proxy server intercepts incoming client calls, then distributes them to multiple backend server instances. Compared to client-side load balancing for gRPC, this approach is easier to implement because there is no need for clients to be able to identify individual server instances. It also makes it easier to implement centralized security or governance controls, since everything flows through the proxy server.
The downside is that server-side load balancing is generally less efficient because the proxy adds another layer. This can increase resource requirements and add to routing delays.
Client-side
Client-side load balancing for gRPC uses logic implemented in gRPC clients or service configs to distribute calls between multiple backend servers for the same service.
To do this, clients must be able to discover backend server instances and route traffic directly to them. Implementing discovery logic adds complexity, but this strategy is more efficient because it is a simpler overall architecture.

gRPC load balancing in Kubernetes environments
While Kubernetes offers built-in load balancing that works at the connection level, this is insufficient for gRPC load balancing because - as we explained above - gRPC load balancing requires the ability to distribute load on a per-call basis, not a per-connection basis.
That said, it’s possible to implement gRPC load balancing for Kubernetes using client-side or server-side solutions:
- On the server side, a proxy like Envoy can serve as an intermediary between clients and Pods. The proxy intercepts calls and distributes them to Pods as appropriate.
- On the client side, admins can configure a Kubernetes headless such that DNS queries return multiple A records for multiple Pods. Then, client application logic determines which Pod should receive each call.
As with gRPC architecture types in general, server-side load balancing is simpler in Kubernetes, but the client-side approach is more efficient and imposes less resource overhead.
Service discovery mechanisms for gRPC load balancing
gRPC load balancing requires services to be able to identify each other on the network. Otherwise, there would be no way to distribute calls efficiently between clients and servers.
The way that service discovery works for gRPC load balancing varies depending on whether you use a server-side or client-side model:
- Under a server-side architecture, you’d typically use a service mesh (such as Istio or Linkerd) to track the identities of backend server instances. A server proxy (such as, again, Envoy) integrates with the service mesh to distribute calls between backend servers.
- With a client-side architecture, the most common approach for gRPC service discovery is to configure a DNS service that can return multiple A records - one for each server instance. Then, the client decides which instance to direct calls to, using the IP address provided by the A record list. If you have a large number of server instances (several dozen or more), it may be more feasible to maintain an external load balancer or service registry and look up server addresses there.
Common gRPC load balancing issues and fixes
A variety of issues may arise in the context of gRPC load balancing. Common problems include:
- Uneven traffic distribution: This occurs when one backend server receives more traffic than others. The most common cause is relying on a traditional, connection-based load balancer instead of a call-based load balancer - so switching to the latter will solve the issue.
- Long-lived streams block rebalancing: Streaming RPCs (server, client, or bidirectional) may stay open for long periods, preventing traffic redistribution even if new backend servers are added. The best way to mitigate this issue is to configure maximum connection age or stream duration allowances on servers.
- New Pods don’t receive traffic: Newly created Pods may not receive traffic because they are ignored by gRPC load balancers. Usually, the reason why is that the load balancer is using outdated network identity data, often due to DNS caching. To solve the issue, turn off caching or use a different service discovery technique (like an external service registry).
Latency spikes: Surges in latency during gRPC load balancing can occur either because traffic is not being distributed evenly (which is usually due to the use of connection-based load balancing, as noted above) or because backend servers become saturated. Concurrency limits can help to mitigate this issue. Allowing multiple requests per backend may also help, since it prevents scenarios where a backend server becomes held up processing a single call.
gRPC load balancing examples
To illustrate how gRPC load balancing works in practice, let’s look at some common scenarios.
Example 1: Client-side round robin load balancing using DNS
- How it works: gRPC clients discover backend servers using a DNS service that returns multiple A records, then distribute calls between them.
- Best for: Scenarios requiring high performance (since client-side load balancing helps optimize performance) and where the number of backend servers is relatively low (maintaining separate A records for each server can become unwieldy at scale).
Example 2: Server-side load balancing (L7 gRPC-aware)
- How it works: A proxy server receives calls from gRPC clients and distributes them to backend server instances. It discovers backend server identities with help from a service mesh.
- Best for: Setups where centralized control over calls is important - for example, if you want to be able to monitor, modify, or block calls, this is easier to do when they all flow through a single proxy server.
Example 3: gRPC load balancing in Kubernetes (service + multiple Pods)
- How it works: A headless Kubernetes service returns a list of IP addresses for multiple Pods using DNS lookups. Each Pod hosts a different backend server. gRPC clients direct calls to specific backend servers.
- Best for: Implementing load balancing in Kubernetes clusters where resource efficiency is a priority (since the alternative approach - server-side load balancing using proxies and service meshes - adds more overhead).
Best practices for reliable gRPC load balancing
The following best practices can help optimize the efficiency and reliability of gRPC load balancing:
- Reduce message size: Generally speaking, smaller is better when it comes to gRPC routing and load balancing. Smaller message sizes enable more granular and efficient distribution of calls between servers.
- Leverage health checks: Although gRPC doesn’t include built-in load balancing, it does offer native health checks that can detect when a backend server is slow to respond, then avoid sending more requests to it.
- Configure timeouts and retries: Enforce deadlines and retry policies for gRPC services to prevent indefinite waits or resource monopolization.
- Choose the right load balancing architecture: If simplicity is a priority, opt for server-side load balancing. Use a client-side approach if you want better performance and have the development resources necessary to implement the requisite client-side logic.
Deep visibility into gRPC load balancing behavior with groundcover
With groundcover, you can quickly identify and resolve gRPC load balancing issues. This is because groundcover alerts admins to problems like high latency or dropped service connections. It also provides the critical context necessary to correlate these issues with insights about the state of your workloads and infrastructure, making it easy to get to the root cause of gRPC load balancing problems fast.
Conquering the intricacies of gRPC load balancing
In some senses, gRPC load balancing is like any other type of load balancing: It simply spreads requests across server instances.
But in other requests, balancing load for gRPC services is unique - mainly because of the need to manage traffic on a per-call basis. This can be done, but it requires the right architectural decisions, load balancing tools, and observability insights for implementing a gRPC load balancing strategy tailored to your organization’s priorities.













.svg)

