Investigating Golang Memory Leak with Pprof
Discover pprof's capabilities in tackling bugs and memory leaks, with a real-life case study examining its impact on performance.

Last Updated: May 12, 2026
Reading the term “memory leak” in the title might have brought up some unpleasant memories for some of you. Indeed, this type of bug can cause immense confusion and frustration for even the most experienced developers. This was exactly the case for us at groundcover - but luckily, we ended up not only solving the issue, but also coming up with some new tricks for the future. Did anyone say “pprof”?
Golang Pprof: The Issue at Hand
Some time ago, we noticed that one of our core services started getting consistent OOM errors during normal operation. Looking at the service’s memory profile showed a textbook memory leak pattern:
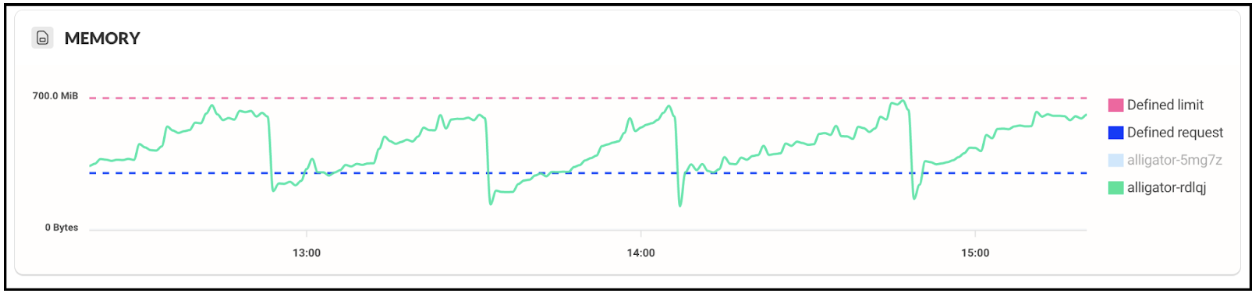
The service starts accumulating memory right from the get-go, growing steadily until reaching the defined memory limits, afterwards it is killed with an OOM error. Bummer.
Memory leaks in go programming language
This is a good time to note that the leaking service is written in pure golang, an open source programming language backed by Google, and the Go programming language—often called the Go language—uses garbage collection as part of the language runtime. This mechanism takes care of freeing unused memory for us, so in theory it should prevent memory leaks from happening; in software development, Go’s static typing and robust standard library also help it stand out from other languages. What’s going on?
From past readings we suspected the issue might have to deal with the runtime not releasing memory back to the OS fast enough - but this was fixed in go 1.16.
Go is also popular for web applications, command line interfaces, and go applications because it helps teams build simple, reliable software.
With no other leads, it was time to get right into the thick of it - using pprof.
pprof and cpu profiling
pprof is one of those tools which make you smile, then cry over time wasted not using them, and then smile again. It’s just that good. Available with the golang installation by default, it’s the pprof tool for analyzing go programs and go code, letting developers easily get extensive profiling data for their applications. This includes a cpu profile, heap profile, goroutine profile, block profile, and mutex profiles as different types of runtime data alongside CPU and memory usage. These profiles help diagnose performance issues, performance bottlenecks, allocations, and cpu time in running programs. To top everything off, it’s incredibly easy to use, requiring one import in your module and a running web server, with built-in web based visualization, and you can also write profile data to a file for later analysis.
The right tool for the job
Since our problem is a memory one, for this test we captured a heap profile with pprof by running the following command:
go tool pprof –-inuse_space http://localhost:6060/debug/pprof/heap
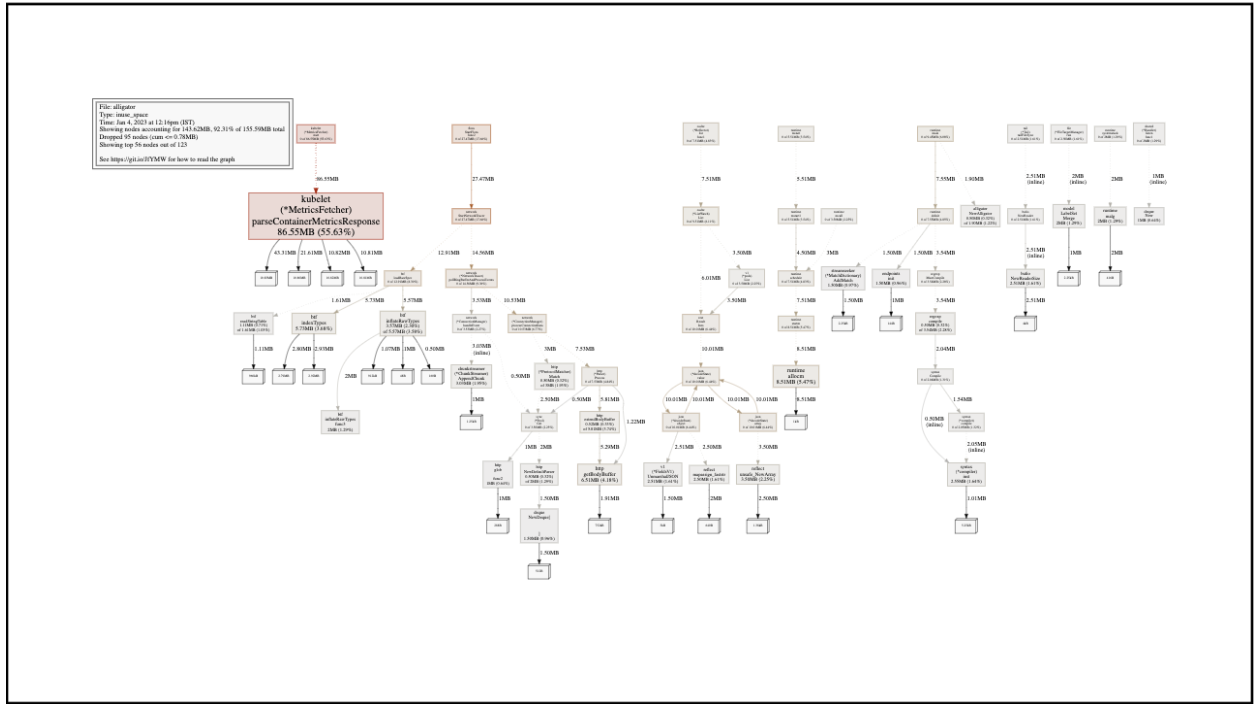
The resulting diagram shows the heap memory currently in use by our service. Red, larger blocks mean more memory; gray, smaller ones mean less memory. The name on the block is the function responsible for the initial allocation of the memory. In other profile views, pprof can also surface the top functions and show which functions consume the most CPU time in CPU-focused profiles, even though this example uses heap data. Note that this doesn’t mean that function is still using that memory, or that the function is even still running - the allocated object might have been passed around to other functions and goroutines.
Our case looks rather simple, with one block popping out immediately:
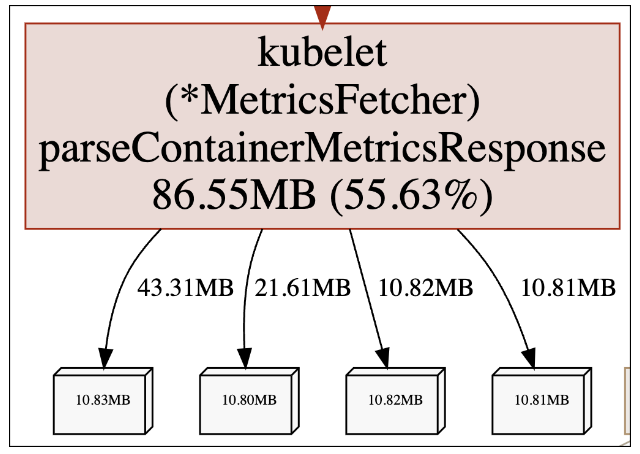
It seems that the MetricsFetcher.parseContainerMetricsResponse function is responsible for the allocation of 55.63% of our current live heap. Knowing our service, this is definitely not intended behavior. To make sure this isn’t a momentarily memory spike, we checked again after a while:
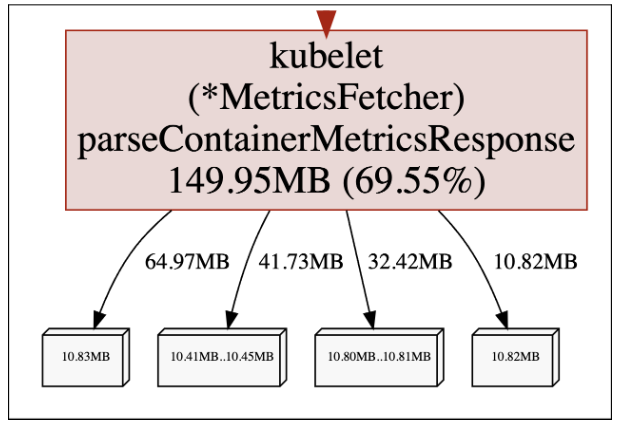
The in-use memory is growing over time! This is consistent with our memory leak pattern, so it seems we might have found the root cause of our issue. Now what?
Enhance!
The function above is simply a parsing function - it shouldn’t keep so much data alive. To improve the application's performance, the real question is why this allocation path stays live after the function returns, even though pprof points to it as the source of the leaky memory.
It’s time to use another amazing pprof feature. Looking at the memory profile above, it doesn’t only track where memory was allocated, but also the entire call flow leading to the allocation! In the next part of the series we will delve into how this mind-blowing feature is implemented. For now, let’s take a look at who called the function:
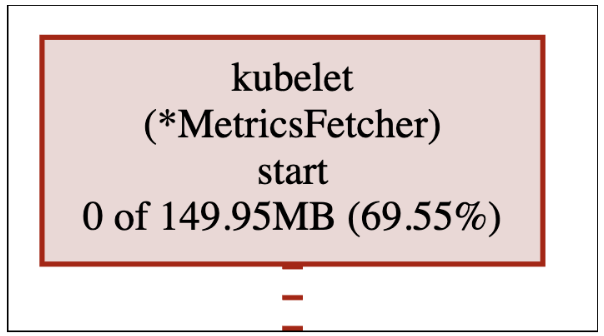
The MetricsFetcher.start starts the call flow which eventually leads to leaking the memory. We can see it generates 0 MB of data itself, but is indirectly accountable for 69.55% of the current live heap - which as we already know, is allocated inside MetricsFetcher.parseContainerMetricsResponse.
This same approach can also uncover other types of runtime problems, not just memory leaks.
To make things even easier for us, let’s use another cool pprof feature that lets us change the graph granularity from functions to lines:

We can now pinpoint the exact lines which eventually lead to allocating the leaky memory - fetcher.go, lines 80 and 142.
It’s all about the flow
Let’s break down the above functions in the relevant go code to understand what goes wrong, including how these programs can keep memory alive through references that look harmless in code review. We already know that leaking flow begins here, in line 80:
This function periodically queries our k8s cluster’s kubelets for monitoring data. It makes sense that it generates a lot of memory, since the responses can get very large. But most of that data is of no interest to us - why are we keeping it?
The response bytes are converted to strings at line 142 (2) and then unmarshalled into rows (3). Note that as seen in our memory profile, (2) is the line which causes the leak - the strings generated here are occupying growing memory over time. Practical examples like this are useful practice for learning how pprof exposes real allocation paths in go apps.
For each unmarshalled row we extract the containerId tag, and then try resolving it into container info:
The cgroupResolver.Resolve() fetches container information and also stores the containerId in a local cache for fast lookups:
A fine line between memory usage, performance and disaster
Some further trial and error made us realize the issue has to do with the resolver caching mechanism - in a production environment, caching bugs like this can hurt operations, especially in long-running services, and remove it from the flow and the problem disappears. The final proof we needed was achieved by changing (5) to add a fresh copy of the container id instead of the unmarshalled one:
Lo and behold, this change fixed the problem. But why?
Thinking again on our findings, this is actually what pprof was telling us this whole time. We know that the memory being leaked are the replies from kubelet - we’ve seen it on the memory profile. Inspecting our business logic also tells us that the only component storing long-term memory is the cached resolver object. The only explanation is the resolver caching the full replies, and not just the short unmarshalled container ids.
But how is this possible? Step (3) involves unmarshalling the response into lines, a process which usually involves creating copies of the data. Perhaps that is not the case?
The response is unmarshalled into rows using the parser.Rows function. But what library is that exactly? Kubelet reports metrics in Prometheus format, and since all groundcover services are built with performance in mind, we used VictoriaMetrics prometheus parser, part of a broader go project built as performance-focused open source software. One can always count on that talented group of engineers when it comes to efficiency :)
So, the parser takes in the raw prometheus format and converts it into readable tags and values. But how does it actually work?
Sharing is not caring
Prometheus responses can get very large - a classic unmarshalling, which generates copies of the parsed data, can be very expensive. For this reason, the library opts for a much simpler solution - “peeking” into the original data using string slicing, without copying anything. In concurrent services, similar patterns can show up with multiple goroutines and shared synchronization primitives during profiling, even when the issue here is string retention rather than lock contention.
While this method is very processing efficient, it is somewhat unintuitive. We are used to passing strings around without thinking too much - that’s the power of garbage collection watching our back alongside string immutability. However, it is always important to keep a close eye on what’s going on. In our case, the seemingly small unmarshalled container ID is actually a slice of the large response string. Caching the sliced container ID means caching the entire response - which is an extremely bad idea. As time passes and more responses are read and parsed, we cache more and more of these monstrous strings - ending in OOM demise.
pprof and trace also help identify patterns across different types of runtime behavior, including block-related contention in block profile data.
The following diagram demonstrates the bug, with the full responses “locked” in memory as long as the cache is holding the “id” subsets:

Conclusion
Finding bugs in production environments is always difficult, which is why pprof stands out as such an incredible tool for go applications in production and broader web development work. The above example demonstrates some of its powerful functionalities - getting a stack trace of the memory allocation site, seeing the culprit in line granularity, and using a CPU profile, heap profile, or goroutine profile as complementary views when diagnosing performance issues. However, for me, the most amazing part is the fact that profiling is turned on by default in all go runtime environments, so there’s absolutely zero reason not to use it. How is this not impacting performance, you ask? Good automated test coverage and solid resources make these techniques easier to apply across projects. That and more in part 2 of the series. For now - happy profiling!
Explore related posts
.png)
.png)
.jpg)
Sign up for Updates
Keep up with all things cloud-native observability.
We care about data. Check out our privacy policy.
Get started
with groundcover
Monitor everything, deploy in minutes.
See the platform in action
Book an on-demand demo with a customer engineer
100% visibility all the time.
Cover your entire Kubernetes stack instantly
with no code changes.
Troubleshoot like a pro.
Auto-detect issues across your entire cluster.
Reduce data & growth costs, dramatically.
See it all. Store what matters. Pay Accordingly.

Done!
Book a demo
Meet the groundcover team for a 30 minute live session
Explore how groundcover provides instant, out of the box insights across logs, traces, metrics, and more.
Get a walkthrough of the platform, pricing model, and real world use cases tailored to modern observability challenges.
Ask anything- our team will address your specific stack, scale, and deployment needs.








By submitting this form you agree to our friendly privacy policy.

.svg)