Lessons from Building an OTel Normalizer for GenAI (Part 1)
What we learned building a GenAI SDK, framework, and provider-agnostic AI observability solution at groundcover.
Everyone says they support OpenTelemetry. However, nobody actually emits the same attributes.This blog post covers what engineers at groundcover learned as we build an GenAI SDK, Framework, and Provider agnostic AI Observability solution.
One of groundcover’s main values is that o11y data collection should be straightforward and unbounded. We believe that SRE’s should focus on addressing incidents and root cause analysis instead of instrumentation, data processing, data gaps, dashboarding, and materialized views. We aim to make AI Observability with OTel as simple as it currently is to collect Infra, APM, and RUM data with our eBPF sensor. Through this process we discovered that there are many hurdles associated with traditional instrumentation. We hope these findings highlight our commitment to building tools that just work and put the power back into the developer’s hands.
How standard is OTel in GenAI?
There's a comforting narrative in the AI observability space, “OpenTelemetry has GenAI semantic conventions, SDKs are adopting them, and soon every LLM call will emit the same standard telemetry. Plug in any backend, get unified visibility”.
We believed this narrative too. Then we tried to actually build it for our AI Observability feature and our Agent Mode, our agentic observability coworker that assists you in addressing incidents by performing root cause analysis within your own cloud.
We spent weeks building a normalizer that ingests GenAI spans from every major instrumentation SDK and produces a single canonical view for any Gen AI data — model, tokens, cost, messages, tool calls — regardless of which SDK emitted the span or which LLM provider was called.
What we found is that the "standard" is more like a suggestion, and the real world is a maze of naming conflicts, structural mismatches, and provider-specific quirks that no amount of spec reading prepares you for.
This post is the field report.
The Setup: What We Expected vs. What We Got
Before we dive into the details of the normalizer let’s take a moment to understand what groundcover offers for AI Observability. We support two paths for capturing GenAI telemetry:
- SDK instrumentation — the customer instruments their app with an OTel-compatible GenAI SDK (Traceloop, LangSmith, the official OTel instrumentations, or manual attributes), and the spans arrive via OTLP.
- eBPF — our kernel-level sensor intercepts HTTP calls to LLM providers (OpenAI, Anthropic, Bedrock) and reconstructs the GenAI semantics from the raw API request/response.
Both paths need to produce the same canonical output. A "chat completion" is a chat completion whether it was captured by Traceloop, LangSmith, or extracted from raw bytes on the wire.
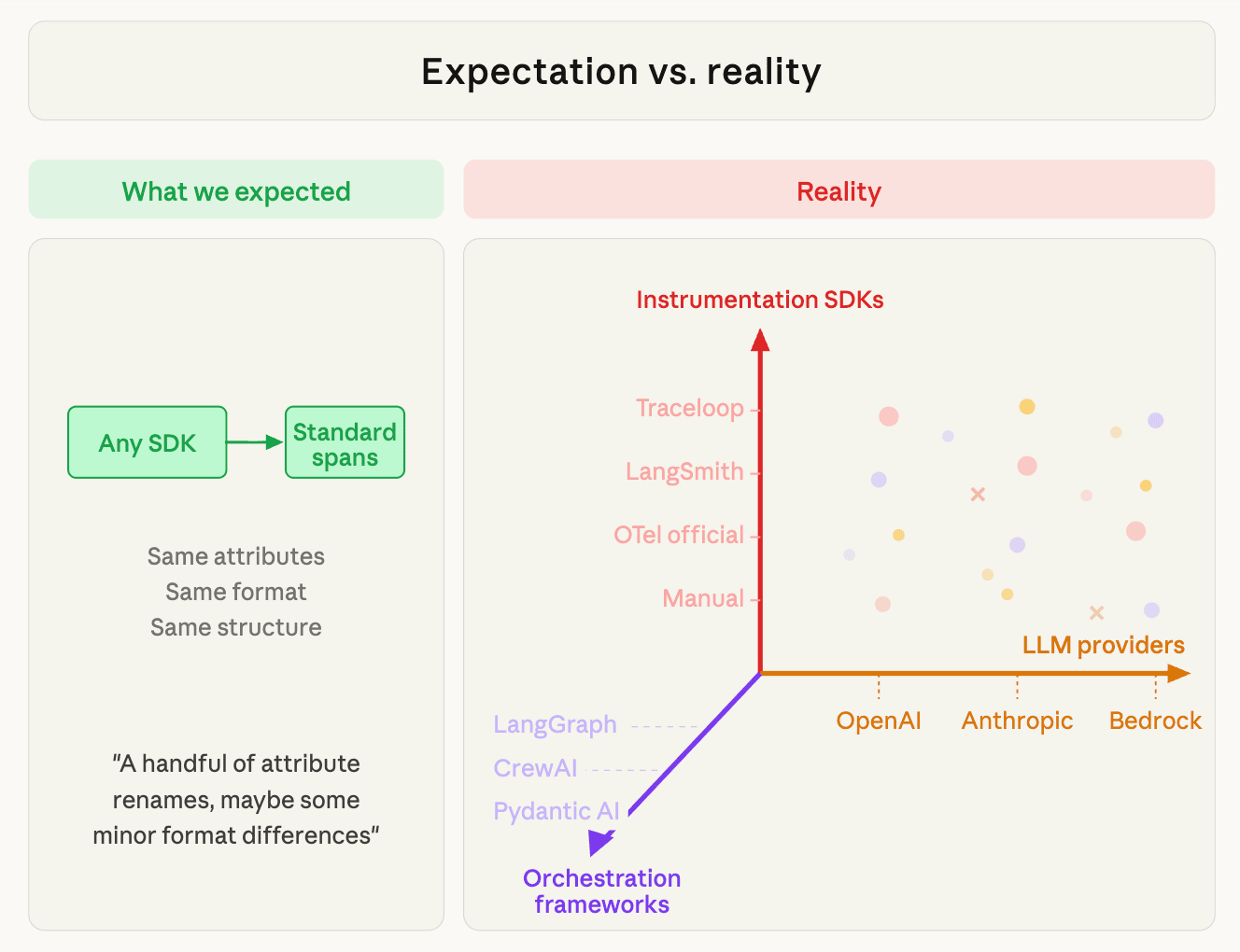
Three Axes, One Canonical Model
The complexity isn't one-dimensional. There are three independent vectors that combine to produce the telemetry we need to normalize:
- Instrumentation SDKs— how the telemetry is emitted. Traceloop, LangSmith, the official OTel instrumentations, or manual `gen_ai.*` attributes. Each SDK emits different attribute names, different message formats, and different token field naming. This is what determines the wire format.
- Orchestration frameworks — how the agent workflow is structured. LangGraph, CrewAI, Pydantic AI, AutoGen, Semantic Kernel, or raw SDK calls with no framework at all. The framework determines the span tree shape (flat LLM calls vs. deeply nested agent → task → tool hierarchies), which metadata appears (conversation IDs, agent names, tool definitions), and how message content is serialized.
For example, LangGraph wraps output in `{"output": [{"update": {"messages": [...]}}]}` state objects. While CrewAI emits its own crew → task → tool span hierarchy and Pydantic AI has a different nesting pattern entirely.
The same provider, instrumented by the same SDK, produces different telemetry depending on the framework. - LLM providers — who is being called. OpenAI, Anthropic, Bedrock, Gemini, Groq, Mistral. Each provider has its own API format, its own token semantics (does "input tokens" include cache?), its own message structure (content blocks vs. content strings), its own tool call format, and its own finish reason vocabulary.
In other words, LangGraph + Traceloop + Anthropic produces different telemetry than LangGraph + Traceloop + OpenAI (provider axis), which is different from the telemetry that CrewAI + Traceloop + OpenAI (framework axis), which is different that that from CrewAI + LangSmith + OpenAI (SDK axis). The full matrix is SDK × Framework × Provider, and each cell can have unique parsing quirks.
The saving grace: the SDK axis collapses into just four wire formats, and the framework axis mostly affects message structure within those formats (not the format detection itself). But "mostly" is doing a lot of work in that sentence.
The four wire formats
Every GenAI span that hits our pipeline comes from one of four formats:
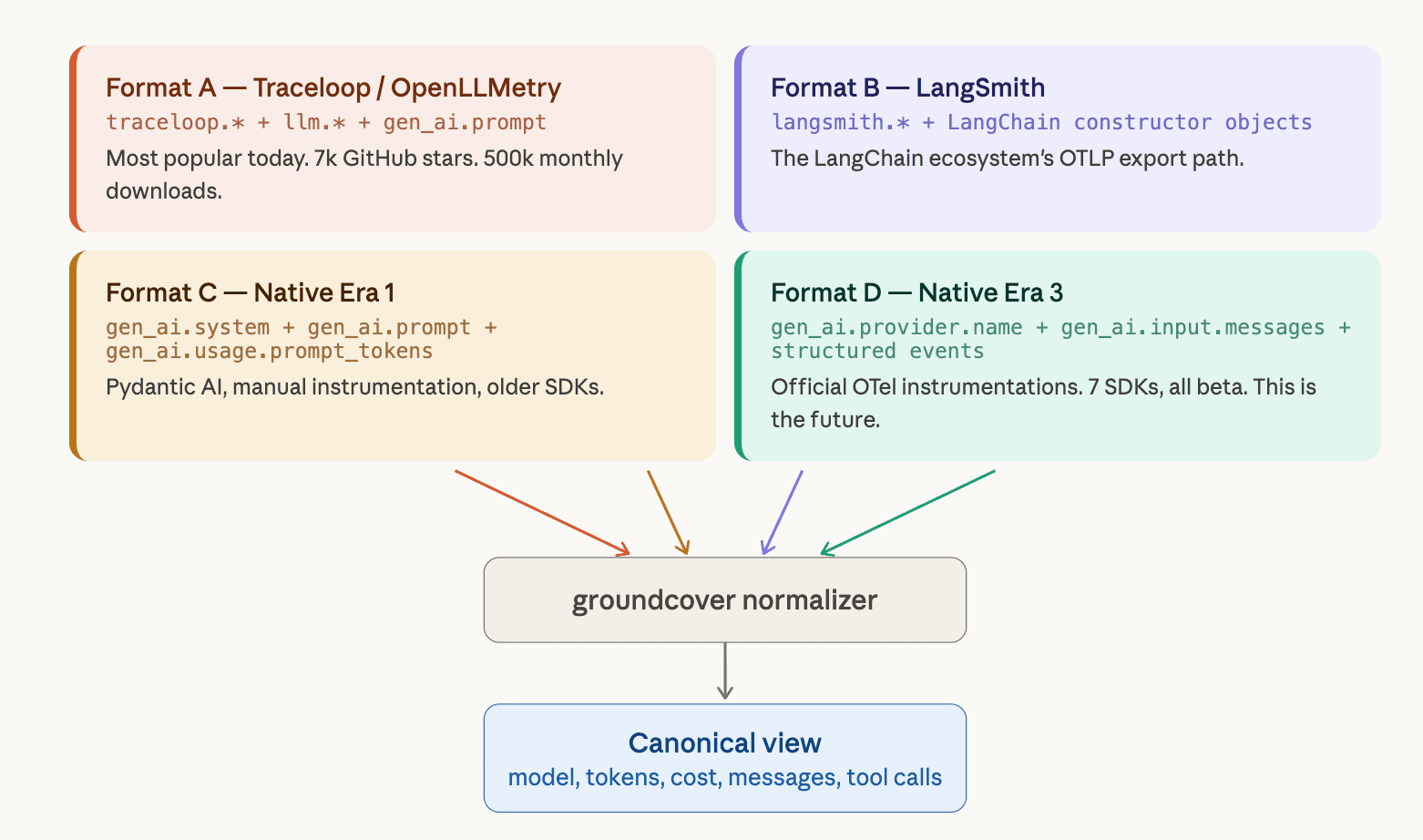
Detecting which format a span uses is the first step. We scan attribute key prefixes. For example, langsmith.* is definitive for Format B. While traceloop.* or llm.* is definitive for Format A. Similarly, gen_ai.* without the others is Format C or D. Then each format gets its own extraction logic, its own message parser, and its own post-processing step before everything converges into a single Field struct.
Formats A through C are fully supported today. Format D — the future standard — is partially supported the core attributes work, but structured event promotion and some message content features are still in progress. Our normalizer closes the remaining gaps as the official OTel instrumentations mature.
A new SDK that uses an existing format with an existing provider requires zero normalizer changes. A new format requires one parser. That's the theory. In practice, the devil is in the details.
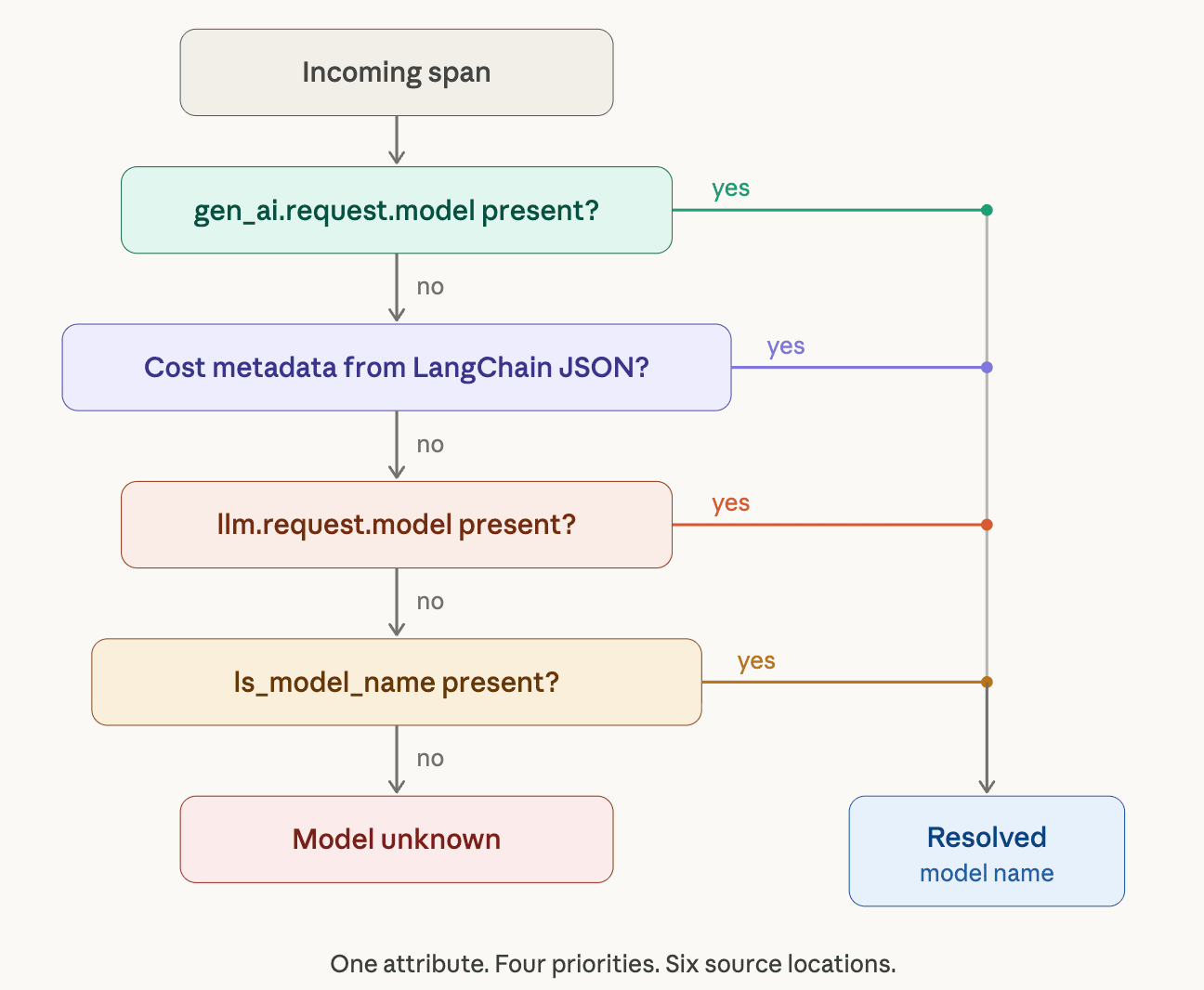
Example 1: "What Model Did You Use?" — Six Ways to Say the Same Thing
The simplest possible question in AI observability: which model handled this request? Here's where six different sources put the answer:

Our normalizer resolves these with a priority chain:
- gen_ai.request.model already on the span? Use it.
- Cost metadata extracted from LangChain message JSON? Use that.
- Llm.request.model` present? Fallback.
- `traceloop.association.properties.ls_model_name`? This becomes the last resort.
Example 2: "How Many Tokens?" — The Naming Chaos
Token counting is the foundation of AI cost tracking. Here's what the ecosystem actually emits:

Five naming conventions for the same metric. Our normalizer resolves them with a three-tier priority chain: canonical names win over cost metadata from LangChain messages, which wins over legacy `prompt_tokens`/`completion_tokens` naming.
Unfortunately we haven’t touched on the hard part yet…
Example 3: Normalizing Cost — When Providers Disagree on What "Input Tokens" Means
Anthropic and OpenAI both report token usage. They disagree on what the number means.

If you don't know that Providers count tokens differently, your cost formula silently undercounts every call that hits the prompt cache.
Our normalizer carries a cacheAdditiveProviders set:
For these providers, cache tokens get added back to input_tokens so the downstream cost calculation ((input - cache_read - cache_creation) * price) produces correct results. For OpenAI, no adjustment is needed because the total already includes cache tokens.
Generic "OTel backends" don’t handle provider-specific token arithmetic. You need normalization to reliably monitor token usage.
Example 4: "Who's the Provider?" — 26 Spellings of 15 Names
Different SDKs emit the provider name differently. Same provider, different strings:
Twenty-six input values, fifteen canonical outputs. Case sensitivity, abbreviations, alternate names — the real world doesn't respect enums. And the list keeps growing as teams adopt AI gateways and proxies (LiteLLM, Portkey, OpenRouter) that add more hosts to recognize on top of the direct provider endpoints.
Final Thoughts for Part 1
In Part 2 we’ll go deeper into messages, parsing, framework-specific span trees, the three eras of OTel Gen AI conventions, and what happens when there’s no SDK at all. But the lessons from Part 1 are clear. There is a big difference between “we support OTel” and “we produce correct, unified telemetry”. The groundcover OTel normalizer for GenAI absorbs the complexity of differing naming conventions, token counts, message payloads, provider names, and much more so DevOps teams can focus on root cause analysis. AI observability should be as simple as installing an eBPF sensor regardless of the providers, frameworks, or SDKs you choose.
.jpg)
.png)
.jpg)










.svg)