Deep Dive into the OTel Normalizer groundcover built for GenAI (Part 2)
Let’s dive into some more examples that highlight the discrepancies in GenAI OTel and complexity involved in making a normalizer.
.jpg)
In Part 1, we showed that "we support OpenTelemetry" means something different to every SDK, framework, and provider. Then we covered the normalization work required just to resolve model names, token counts, and provider spellings. This post covers messages, frameworks, the three eras of OTel GenAI conventions, and what happens when there's no SDK at all. Let’s dive into some more examples that highlight the discrepancies in GenAI OTel and complexity involved in making a normalizer.
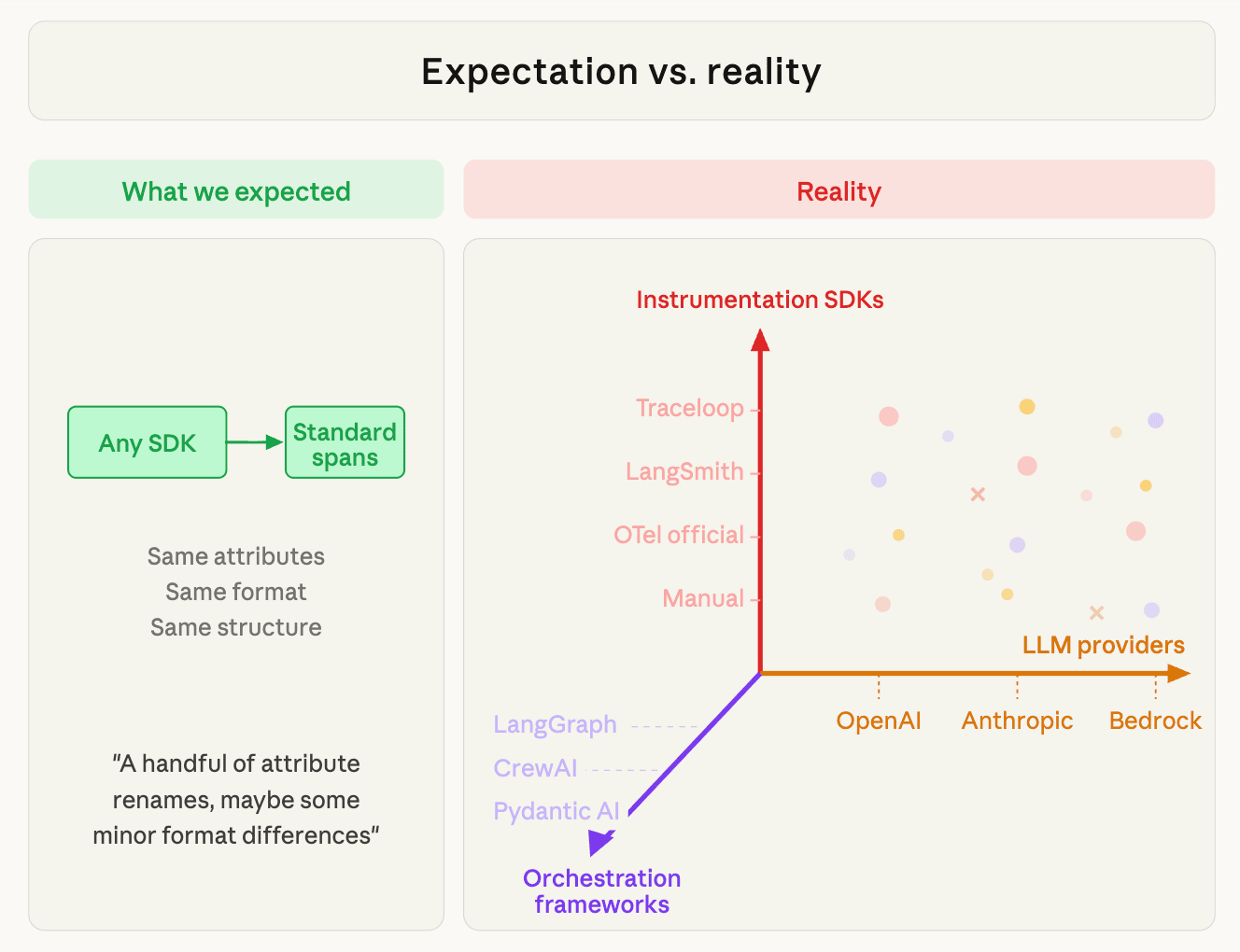
We expected a handful of attribute renames, maybe some minor format differences. What we found was a three axis problem of complexity in the OTel for GenAI space.
Example 5: Three SDKs, Three Completely Different Message Structures
Ask three SDKs to represent the same conversation — a user saying "Hello" to Claude — and you get three radically different data structures.
Traceloop emits indexed span attributes:
LangSmith wraps everything in LangChain constructor objects:
eBPF captures the raw Anthropic API body:
All three need to be normalized into one canonical format:
Traceloop's indexed attributes need to be reassembled from flat key-value pairs. LangChain's constructor objects need to be unwrapped. The raw API body needs Anthropic's content-block array normalized to the parts schema. Each path is a separate parser.
And then there are tool calls Anthropic puts them inside `content` blocks. OpenAI puts them in a separate `tool_calls` array at the top level. LangChain wraps both in constructor objects. Same semantic action — model wants to call a function — three completely different JSON structures.
Example 6: The Framework Dimension — Same SDK, Same Provider, Different Shapes
This is the one that surprised us most. Take the same instrumentation (LangSmith) calling the same provider (Anthropic) — but change the orchestration framework, and the telemetry changes shape.
A direct LangChain ChatAnthropic call produces an LLM span with constructor-format messages and a flat completion:
The same call routed through a LangGraph agent wraps the output in a state update envelope:
Same SDK. Same provider. Same wire format. But the message parser that handles the first structure fails on the second (the output[].update.messages[] envelope is LangGraph-specific and requires its own extraction logic).
CrewAI adds yet another dimension: its span tree LLM calls and tools with crew-level metadata (agent roles, task descriptions, delegation chains) that no other framework emits. The span hierarchy itself carries semantic meaning that a flat normalizer misses.
This is why "SDK × Provider" isn't the full picture. The framework determines how message content is wrapped, how span trees are nested, and what metadata exists. A normalizer that handles Traceloop + Anthropic but doesn't account for LangGraph's state envelope will silently dump raw JSON instead of a readable conversation — which is exactly the kind of bug we're still fixing.
Example 7: The Three Eras of OTel GenAI Conventions
The OTel GenAI semantic conventions have gone through three major revisions in under two years:
.png)
The unfortunate reality is that most production traffic today is still stuck in Era 1. Traceloop (the most popular GenAI instrumentation with 500k monthly downloads) emits Era 1. LangSmith emits Era 1. The official OTel instrumentations emit Era 3, but they're all beta and have minimal production adoption so far.
The renames between eras aren't just cosmetic:
A backend that only supports Era 3 attributes breaks on 90%+ of real production traffic. A backend that only supports Era 1 misses the structured data in Era 3 spans. You have to support both, plus the transition period where some attributes from each era appear on the same span.
Example 8: The eBPF Angle — When You Don't Have an SDK at All
For teams that haven't instrumented their code yet, our eBPF sensor captures LLM API calls from the wire — no SDK needed. The sensor sees raw POST /v1/messages to api.anthropic.com, parses the JSON request and response bodies, and reconstructs the GenAI semantics: model, tokens, messages, tool calls, finish reason.
This is still maturing. The eBPF path works well for straightforward API calls, but we're still working through edge cases like compressed response bodies, truncated payloads, streaming responses. These require careful handling at the kernel level. It's valuable as a zero-instrumentation on-ramp and a source of wire-level ground truth, but it comes with its own normalization challenges:
- The request body has the model name, messages, and parameters — but in the provider's native API format, not OTel's.
- The response body has token counts, finish reasons, and output content — again in provider-native format.
- Anthropic uses stop_reason: "end_turn" whereas OpenAI uses finish_reason: "stop"`.
- Anthropic uses tool_use content blocks; OpenAI uses a tool_calls array.
- The eBPF path and the SDK path must produce compatible output — same attribute names, same message schema, same token semantics — or downstream queries break.
We maintain separate parser packages for each provider (Anthropic, OpenAI, Bedrock), each mapping provider-specific API responses to the canonical GenAI schema. The hardest part isn't the initial implementation. It’s actually keeping two independent code paths in sync. When the sensor and the SDK normalizer drift (different JSON part names, different attribute keys), we get silent data inconsistencies that only surface when a customer queries across both sources. We're investing in contract tests (i.e. feeding the same API payloads through both paths and asserting identical output) to catch this drift before it reaches production.
Why We Bet on OTel Anyway
After all this you might ask: why not just pick one SDK, mandate it, and move on?
Because we've seen this movie before. Every generation of infrastructure tooling goes through a fragmented phase before a standard wins. HTTP had competing server APIs before CGI and then WSGI. Metrics had StatsD, Prometheus, and vendor agents before OTel Metrics converged them. Tracing had Zipkin, Jaeger, and vendor-specific formats before OTel Tracing became the substrate. Even though GenAI telemetry is in the messy middle right now, the trajectory is evident.
The alternative to OTel is proprietary lock-in. Datadog's LLM Observability requires ddtrace with _ml_obs.* attributes that only flow to Datadog. LangSmith's richest telemetry requires LangChain. Every dedicated AI observability tool has its own SDK, its own schema, and its own backend. Teams that adopt one are locked into it. Switching means re-instrumenting every service.
OTel is the only path where the customer instruments once and retains the freedom to choose (or change) their backend. That's table stakes for us. groundcover runs in the customer's cloud — prompts, tool call arguments, agent reasoning chains never leave their environment.
We don't ask teams to send their most sensitive data to a SaaS vendor. But that architecture only works if we accept telemetry in the formats customers actually emit, not the format we wish they'd emit.
And there's a deeper reason. Our customers aren't AI-native startups building a chatbot. They're engineering orgs shipping AI capabilities inside larger systems. Their agents call databases, APIs, and microservices that groundcover already monitors. An LLM call that times out might be a model problem or a network problem or a pod OOM-kill. The answer is in the correlation between the GenAI trace and the infrastructure telemetry — and that correlation only works when both live in the same platform, on the same timeline, in the same query language. AI observability bolted onto an existing full-stack platform beats a standalone AI monitoring tool that can't see the infra underneath.
So yes, normalization is painful. But forcing customers onto a proprietary SDK, or only supporting one instrumentation library, or shipping a standalone AI tool disconnected from infra is worse.
We absorb the complexity so customers can focus on their product.
Summarizing What We Learned
Lesson 1: The standard exists on paper. The ecosystem hasn't converged.
OTel GenAI semantic conventions are well-designed. The problem is timing: the spec is still experimental, it's on its third major revision, and the most popular SDKs haven't migrated yet. For the next 12-18 months, any serious GenAI observability backend needs to support all eras simultaneously.
Lesson 2: Provider-specific semantics leak through every abstraction.
Token counting, message structure, tool call format, finish reasons, cache behavior — providers do these differently at the API level, and no SDK fully papers over the differences. A normalizer that treats all providers identically will silently produce wrong cost numbers (cache tokens), miss tool calls (different JSON structures), or misinterpret completion status (different stop reason values).
Lesson 3: Separating the axes is what makes it tractable.
The full matrix is SDK × Framework × Provider — which sounds like a combinatorial explosion. But the axes are genuinely independent: the SDK determines the wire format, the provider determines field semantics and token math, and the framework determines message envelope structure and span tree shape. A new SDK that uses an existing format requires zero normalizer changes. A new provider requires one field mapping. A new framework requires handling its message envelope — but only within the format it already uses. Keeping these axes separate in the architecture is what prevents the matrix from becoming unmanageable.
Lesson 4: eBPF is ground truth — in principle.
When SDK and eBPF attributes conflict for the same LLM call, the wire-level data should win. The sensor sees actual traffic — real model names (including version suffixes the SDK strips), real token counts, real response times. SDK spans are second-hand: instrumentation library interpretation, potentially stale SDK versions, manual instrumentation errors. We're building toward eBPF as the authoritative source for cost-relevant fields, but the eBPF path is still maturing — handling compressed responses, large payloads, and keeping schema parity with the SDK normalizer are active work.
Lesson 5: The convergence is coming, but slowly.
Era 3 of the OTel spec is well-designed and comprehensive. The official instrumentations for OpenAI, Anthropic, Google, and Vertex AI all emit it. Traceloop has a migration PR open. In 12-18 months, Format D will dominate and the normalization burden will shrink dramatically. But "12-18 months" is a long time in production, and teams shipping AI agents today can't wait for the ecosystem to converge.
Final Thoughts The Bottom Line
"We support OpenTelemetry" is the beginning of the conversation, not the end. The real work is in the normalization layer.
The challenge is in all the code that takes llm.usage.prompt_tokens from Traceloop and usage_metadata.input_tokens from a LangChain JSON blob and usage.input_tokens from a raw Anthropic API response and produces one canonical gen_ai.usage.input_tokens value that downstream dashboards, cost calculations, and alerting can rely on.
We're building that layer. It already handles four wire formats, three spec eras, six providers, 26 provider name variants, two sources of token data that mean different things depending on the provider, and message structures that range from flat key-value pairs to deeply nested LangChain constructor objects. And it needs to produce the same canonical output whether the data came from an SDK or from raw bytes captured by an eBPF probe in the kernel.
It's not done. There are edge cases in the eBPF path, gaps in Era 3 support, and message parsing bugs we're still squashing. But the architecture is right: detect format, extract per-source, normalize to canonical, handle provider quirks. Every week the coverage matrix gets fewer blank cells.
That's what AI observability actually looks like in production. Not a standard — a translation layer that makes the standard real. And it's never finished, because the standard isn't finished either.
.jpg)
.png)
.jpg)










.svg)