Log Sampling: Techniques, Challenges & Best Practices

Logs give you the visibility you need to understand what is happening inside your systems. As your infrastructure grows, the number of log entries grows with it. Traffic spikes, new features, and short incidents all increase the volume of data your monitoring stack must process. Imagine a checkout flow that depends on a payment provider. If that provider stops responding for only a few seconds, every purchase attempt during that window fails and generates an error log. A small disruption suddenly turns into thousands of entries that must be collected, stored, and analyzed.
This is where log sampling becomes essential. Instead of collecting every single event, sampling allows you to keep enough data to understand the issue without overwhelming your systems or your budget. It helps you reduce noise, maintain observability during incidents, and stay within cost limits while still having the information you need to troubleshoot. To apply sampling effectively, you need the right techniques, clear policies, and an understanding of the risks that come with discarding data.
What is Log Sampling?
Log sampling is the process of keeping only a selected share of log data rather than storing every log entry. The goal is to retain enough logs to understand what is happening in your systems while preventing the volume from growing faster than you can manage. You create rules that determine which logs should stay, and those rules reflect the information you want to preserve for monitoring and troubleshooting.
Sampling becomes useful once logs start to scale beyond what you need. Many logs repeat the same information, especially during issues. By collecting just a fraction that still represents the underlying behavior, you cut storage and ingestion costs while keeping visibility into patterns that matter. It allows you to continue analyzing logs effectively as your environment expands.
Log Sampling vs Log Filtering
Sampling and filtering both reduce how many logs you store, but they protect different kinds of visibility:
Using both together ensures you remove noise without losing the visibility you depend on when something breaks.
Why Log Sampling Matters in Modern Observability: Key Benefits
When systems scale, log data grows faster than almost any other telemetry. Every user action, retry, and background task generates more entries. Log sampling ensures your monitoring and analytics tools continue to reveal what is actually happening inside your environment, even as the volume becomes harder to manage. Here is why sampling plays an important role:
- Keeps diagnostic details visible during incidents
Failures rarely appear as a single log. They show up as a sudden spike in repeated errors. If your ingestion pipeline becomes overloaded, those logs may never make it to storage or dashboards. Sampling ensures that even when the failure rate multiplies, a reliable portion of those logs still arrives in your observability stack. - Protects the ingestion and processing pipeline from overload
Observability platforms must handle logs in real time. When input volume rises sharply, systems can slow down, fall behind, or start dropping data. By limiting how many logs enter the pipeline, sampling prevents cascading delays that would otherwise hide real issues while they are still unfolding. - Improves search performance and analytical accuracy
High-volume logs create noise that slows down queries and makes dashboards harder to use. Sampling creates a tighter, more useful dataset. This makes investigations clearer because the irrelevant noise has been reduced before analysis begins. - Controls long-term storage obligations and data growth
Logs accumulate quickly. When stored without limits, they drive up costs for retention, indexing, and backup. Many logs are never used again after ingestion. Sampling ensures that logs contributing no new insight are discarded early. This means storage reflects the value of the data kept, not the volume of activity in the system. - Ensures attention remains on meaningful behavior changes
If every event is stored, unusual patterns become harder to detect. Logs that reveal user impact, like slow responses, denied permissions, or unusual traffic, blend into the background. Sampling prioritizes what changes rather than what repeats. This helps you spot drift sooner and respond before users notice. - Supports reasonable data retention for compliance
Many organizations do not need to keep all logs forever. They need to preserve what proves correctness, security, or operational continuity. Sampling gives you a structured way to reduce retention volume without random or risky deletions later in the lifecycle. The logs that remain still tell the story that auditors may need. But keep in mind that some industries, such as finance and healthcare, require full retention of certain logs for compliance.
These benefits form the foundation of why sampling is used not only to save money but to maintain reliable observability as systems evolve. But not all sampling methods are the same.
Types of Log Sampling Techniques
There is more than one way to reduce log volume while keeping important information visible. Each sampling technique approaches that goal differently, and the choice depends on how predictable your traffic is and what level of accuracy you need during incidents.
Random Log Sampling
Random sampling keeps a log entry based on probability. If you set a 10 percent sample rate, roughly ten out of every hundred logs will be stored. Each message has an equal chance of being selected, which makes the method simple to configure and fair across the log stream.
This approach is easy to implement, but because it relies on randomness, you may still miss rare or bursty events.
Systematic (Fixed-Interval) Log Sampling
Systematic sampling follows a predictable pattern rather than probability. Logs are kept at regular intervals, such as every 100th message. This ensures even coverage across time and avoids bias from randomness. This approach is effective for long-running streams, but bursts of unusual activity between selected intervals might go unseen.
Stratified Log Sampling
Stratified sampling first divides logs into meaningful categories. This may be log level, service, region, etc. It then applies a different sampling rate to each group. Critical events remain fully visible while noisier categories are reduced. This technique maintains balanced visibility across the system and prevents high-volume success logs from hiding more important patterns, though it requires more configuration.
Adaptive or Dynamic Log Sampling
Adaptive sampling adjusts retention in response to real-time conditions like traffic spikes or error surges. When everything is healthy, sampling is aggressive. When errors rise or latency increases, sampling loosens to capture more context. This makes logging cost-efficient during steady operation while protecting visibility when something goes wrong. It does require smart tuning so the system adjusts only when truly necessary.
How Log Sampling Works
Sampling fits into the logging pipeline as a sequence of decisions that determine which logs move forward and which ones are safely dropped. Each step protects visibility while keeping volume under control. Below are the main steps of log sampling:
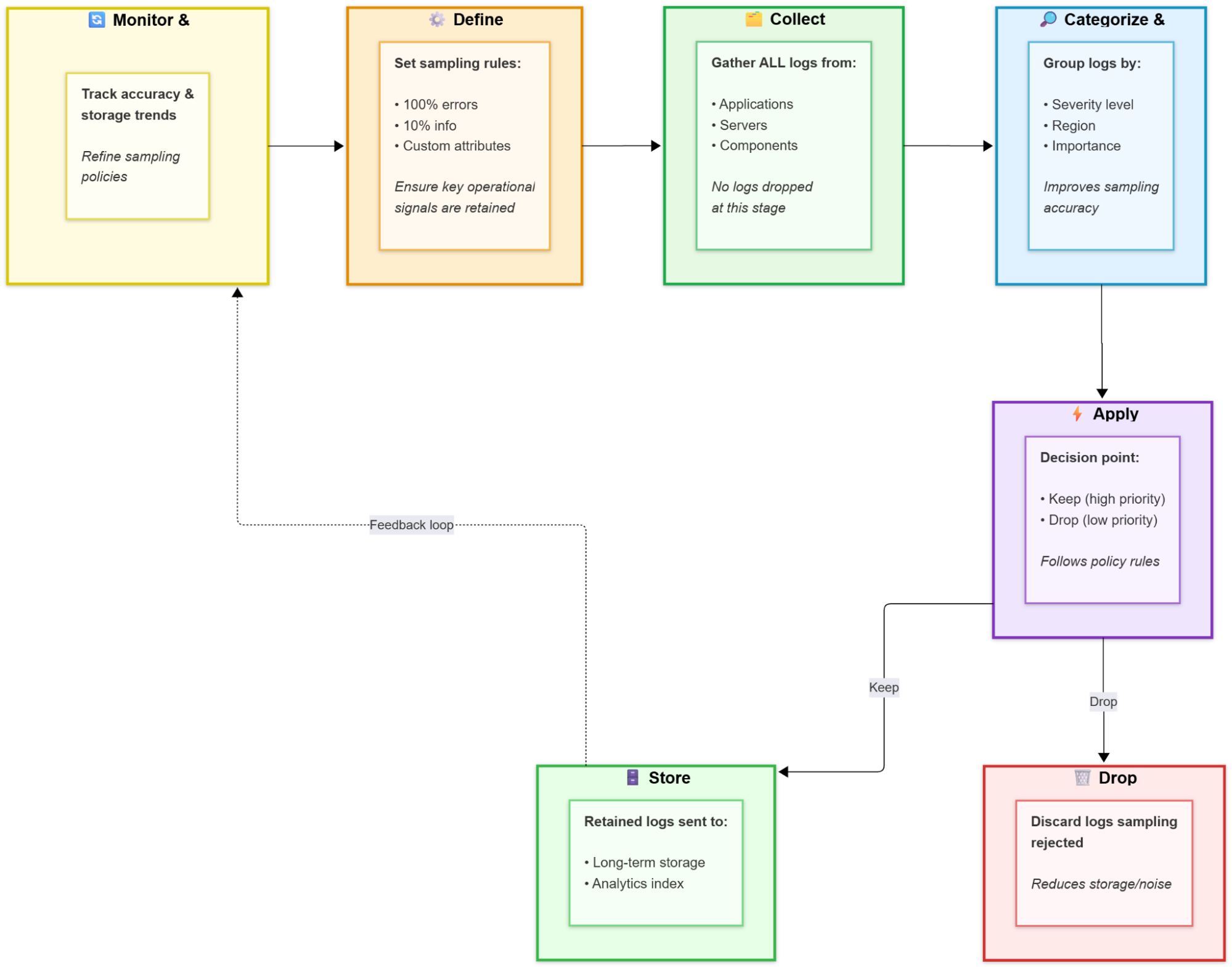
Step 1: Define sampling policies
The process begins by deciding what should be kept. Not all logs have equal value, so you should create rules that reflect operational priorities. Take a login service handling user authentication across different regions, for instance. Every failed login attempt exposes real user friction or a possible security risk. Those logs are worth retaining. Successful authentications often repeat the same information. Keeping only a percentage of them still shows the overall pattern of user behavior without storing every attempt. These rules may target log levels such as keeping 100 percent of errors and 10 percent of informational logs, or apply to custom attributes like region or latency. The goal is to determine what signals must always remain visible.
Step 2: Collect logs from every source
Once policies are defined, the system begins collecting logs from applications, servers, and supporting components. All incoming data is observed at this stage so that sampling decisions are made with a complete view of the system’s behavior. At this point, nothing is removed. Every log enters the evaluation flow equally.
Step 3: Categorize and filter before sampling
Before a keep-or-drop decision happens, logs are grouped or labeled to give the sampling engine context. A successful authentication can be classified as a low-risk, high-frequency event, while a denied login or repeated failure carries more operational importance. Classification ensures that sampling does not treat all logs the same. Grouping also improves performance later because rules are enforced per category rather than per message.
Step 4: Apply the sampling algorithm
When each log reaches this stage, the system decides if it moves forward based on the defined policies. The logging agent applies the selected sampling method, following the configured rules to retain logs according to priority or probability, ensuring that essential events remain visible while overall volume stays controlled.
Step 5: Store selected logs
Only the logs that sampling approves flow into long-term storage and indexing. Everything else is dropped. The retained entries still tell the full story of how the login system behaved depending on the sampling method you chose.
Step 6: Monitor and adjust
After sampled logs are stored, the system must evolve with changing conditions. If alerts lose accuracy or anomalies become harder to detect, update the sampling rules to restore visibility. Evaluating detection quality and storage trends over time helps keep the balance between insight and cost.
As you’ve seen, sampling helps control log volume while preserving visibility. But is it always necessary to use log sampling?
When to Use Log Sampling
Not every environment requires log sampling, but the need becomes clear as systems scale or budgets tighten. Sampling is most effective when log streams grow faster than your ability to process or store them. It helps you stay observant without collecting redundant or low-value data. Here are the scenarios where applying sampling provides the most value.
High-volume environments
Systems that produce continuous streams of logs, such as trading platforms, large e-commerce sites, or social media backends, generate massive throughput. Each request, retry, or background operation can add thousands of entries per second. In these conditions, sampling prevents the ingestion layer from being overwhelmed while still preserving a statistically accurate view of what’s happening.
Cost or storage constraints
Small businesses, IoT networks, and edge devices often have limited storage or bandwidth. In these cases, sampling allows conservation of resources without sacrificing awareness. The goal is to spend storage on what provides insight rather than volume.
Real-time monitoring needs
Monitoring pipelines that power live dashboards or alert systems must remain responsive. High log volume can delay or block alerts if queues fill faster than they can be processed. Sampling controls this flow, ensuring that operational metrics remain timely. For example, a security operations team might keep every warning and error-level log but apply strong sampling to routine informational messages. This maintains responsiveness without losing situational visibility.
Burst or spiky traffic
Some systems face unpredictable surges, such as promotional events, seasonal traffic, or partial outages that multiply log volume in minutes. Sampling helps absorb these spikes without flooding log processors.
Continuous operations
Long-running systems that produce repetitive logs over time benefit from scheduled or rolling sampling. Keeping every success message indefinitely leads to exponential growth in archives. By periodically sampling operational logs, for instance, once every hour or per batch, you can retain the structure of normal activity while focusing full attention on new anomalies and incident-related data.
Log sampling, therefore, is not a one-size-fits-all practice. You should decide when it is worth applying.
Use Cases of Log Sampling
Log sampling is adopted across different architectures and operational setups. Each environment has its own reasons for reducing log volume while maintaining visibility. Here are some of the most common use cases where sampling delivers measurable benefits.
- Microservices and distributed systems
Large-scale microservice environments generate high volumes of logs from multiple services running in parallel. Sampling ensures that backend systems remain responsive and that teams can still analyze meaningful patterns without overwhelming storage or indexing tools. In a payment platform, high-frequency informational logs might be sampled heavily while all payment failure logs are retained in full for debugging and compliance. - DevOps and SRE practices
Operations teams use sampling to keep observability dashboards useful and current. By sampling Kubernetes cluster logs based on pod count or node activity, you can monitor performance trends without pulling in every low-level event. This keeps visualization tools responsive and focused on changes that affect stability or availability. - Big data pipelines
Data processing platforms such as Spark or Hadoop generate logs for every task and subtask. Sampling a small, representative subset of those logs helps quickly debug failed jobs or performance bottlenecks without processing terabytes of redundant output. - Web and e-commerce sites
High-traffic web applications produce millions of access and request logs daily. Sampling helps track performance, latency, and conversion trends without storing every page view. Keeping only a small fraction of logs can still show clear usage patterns, making capacity planning and performance tuning easier while keeping query costs low. - IoT and edge computing
Devices deployed at the edge or in remote areas often have strict bandwidth and storage limitations. Sampling makes telemetry collection practical in these conditions. By forwarding only a portion of sensor readings or device logs, teams maintain visibility into operational trends without overloading constrained hardware or networks.
This shows sampling is not just a data reduction tactic but an operational strategy for sustainable observability. However, while log sampling reduces data volume and cost, it also introduces trade-offs that should be managed carefully.
Challenges of Log Sampling
Deciding what to keep and what to discard can affect visibility, accuracy, and compliance. Challenges often emerge as systems grow or when sampling is configured without clear operational goals:
Best Practices for Log Sampling Implementation
Successful log sampling depends on clarity, adaptability, and continuous validation. The following best practices will help you maintain meaningful visibility while keeping log volumes under control.
- Define clear criteria
Establish what should be sampled and what must always be retained. ERROR and WARN logs should typically be collected in full, while informational and debug logs can be sampled at smaller percentages. Use factors such as severity, service type, or user activity to determine rules. - Balance sample size and accuracy
Sampling effectiveness relies on maintaining enough data to preserve accuracy while staying within storage and processing limits. More logs increase reliability, but also cost. Regularly verify that sampled data still captures key patterns, especially for metrics like error rates and latency distributions. When critical trends begin to blur, increase sampling rates for the affected areas. - Use automated and adaptive techniques
Automation helps maintain consistency as systems evolve. Employ adaptive sampling that adjusts in real time based on system load or event type. For example, routing logs through an OpenTelemetry Collector with dynamic filters allows the system to raise sampling rates during anomalies or spikes and lower them during stable operation. - Combine multiple methods
No single sampling approach fits every scenario. Combine techniques to improve efficiency and resilience. Random sampling can manage high-volume logs, while stratified or time-based sampling ensures fair representation across services and workloads. - Iterate and review continuously
Sampling strategies should evolve alongside applications. Review logs regularly to compare sampled data against full data when available. If critical signals or alerts are missed, adjust sampling parameters. Iterative refinement prevents performance drift and ensures sampling remains aligned with operational goals. - Validate before production
Before deploying sampling configurations live, test them using mirrored log streams or sandbox environments. This helps confirm that essential alerts still fire and that system insights remain accurate. Simulating various load conditions during testing reveals how rules perform in both normal and peak scenarios. - Document sampling policies
Keep detailed documentation of your sampling strategy, rationale, and rules. This transparency helps teams understand why certain logs are missing and ensures compliance with auditing requirements. Clear documentation also simplifies onboarding and policy reviews. - Monitor for drift
Even with automation, drift can occur when log volume or event types change. Implement counters and alerts that track deviations between expected and actual sampling behavior. For example, if error rates spike but the sampling ratio remains static, the system should temporarily raise sampling levels. - Use contextual signals
Link sampling decisions to other observability signals such as metrics or traces. When latency, error rates, or resource consumption rise in a specific service, temporarily increase its sampling rate. This context-aware approach ensures the most relevant logs are captured precisely when they matter most.
When you want the best results from log sampling, success relies not only on following best practices. It also depends on choosing the right tools and technologies throughout your logging stack.
Tools and Technologies for Log Sampling
Modern ecosystems offer several ways to manage log sampling.
- Logging libraries
Most programming languages now support built-in sampling. In Go, zerolog and zap define sample rates per log level. Java’s Log4j2 and Logback use filters or appenders to drop repetitive logs. Python’s logging module allows custom Filter classes, while .NET’s Microsoft.Extensions.Logging includes configurable probability-based sampling. - Log shippers and agents
Tools such as Vector, Logstash, and Filebeat can apply sampling before ingestion. Vector’s sample transform keeps a fraction of logs. These early-stage filters help prevent data overload before logs reach storage. - OpenTelemetry
The OpenTelemetry Collector offers head-based and tail-based sampling through processors, ensuring logs and traces remain consistent across the pipeline. It allows unified control over telemetry data without introducing bias. - SIEM and observability platforms
Security and monitoring tools use ingestion rules to retain critical events and discard low-priority logs. This selective approach maintains visibility while optimizing storage and compute resources. - Database and queue integrations
Platforms like Kafka, ClickHouse, and Elasticsearch support sampling at write or query time. Kafka producers may publish selected messages, while ClickHouse queries can process sampled subsets for faster analytics. - Contextual observability integration
Some modern observability platforms, such as groundcover, integrate log, metric, and trace correlation to simplify sampling decisions and enhance visibility.
Groundcover takes contextual observability a step further, offering a unified platform.
How groundcover Simplifies Log Sampling with Contextual Observability
groundcover reduces the pressure for aggressive sampling. Instead of trading visibility for cost control, its architecture allows you to capture every event while maintaining performance, compliance, and affordability.
- Volume-Agnostic Log Ingestion
With groundcover, you can collect every log generated across your environment without worrying about exceeding storage quotas or data limits. The pricing is simple; costs are determined by how many hosts or Kubernetes nodes you monitor, not by the size or volume of your log data. This means your expenses stay consistent even during high-traffic periods, allowing you to maintain full observability as systems grow and activity increases. - Context-Rich Log Collection
Every log is captured directly from each Kubernetes pod at the kernel level with eBPF technology. groundcover automatically enriches log entries with metadata, such as labels, pod and container information, and relevant service details. This richer context makes it easier to trace issues, correlate events, and understand system activity at a granular level, even if some logs are sampled upstream. - Scalable Storage and Instant Search
All logs, traces, and metrics are securely stored in a ClickHouse backend. groundcover’s Log Explorer gives you real-time access to your telemetry data, allowing for instant searches, filters, and analysis. You can explore trends, patterns, and anomalies across multiple data streams quickly. - Unified Observability and Adaptive Pipelines
Logs, metrics, and traces are displayed together in one intuitive dashboard, so you always see the complete operational picture. Groundcover also enables adaptive, no-code pipelines, allowing you to fine-tune log retention policies dynamically. You can easily prioritize error logs or key events while reducing less critical, repetitive log entries based on current needs.
By merging log collection, enrichment, and analysis into a single workflow, groundcover reduces the necessity for aggressive upfront sampling by handling volume efficiently. This allows teams to focus on insights rather than data volume.
FAQs
What’s the difference between log sampling and log aggregation?
Log sampling reduces volume by keeping only part of the log stream, while log aggregation collects all logs from multiple sources into one place for analysis. Aggregation centralizes data without reducing it; sampling selectively stores logs to control cost and noise.
How can teams ensure that log sampling doesn’t miss critical anomalies or alerts?
Use targeted sampling rules and adaptive strategies. Always retain all error-level and transaction logs, while sampling routine informational ones. Stratified and adaptive sampling help maintain visibility, and correlating logs with traces and metrics ensures anomalies aren’t overlooked.
How does groundcover provide full observability even with sampled logs?
Groundcover uses eBPF-based collection to capture logs, metrics, and traces together at a fixed cost. Even when logs are sampled at the source, its context-rich platform correlates them with related telemetry, preserving full visibility for troubleshooting and analysis.
Conclusion
Log sampling gives you a practical way to control log growth while keeping the visibility you need to detect and resolve issues quickly. By applying clear rules, adaptive methods, and continuous validation, you can reduce data volume without losing critical insight. Tools like groundcover take this further by providing full-context observability across logs, metrics, and traces at a fixed cost, allowing you to focus on understanding system behavior instead of worrying about data limits or missed signals.





.svg)