Deadlock Detection in Operating Systems: Algorithms, Recovery & Best Practices


On a highway, gridlock happens when multiple cars want to be in the same place at the same time, which creates obstructions that hold up traffic for everyone. A similar phenomenon, known as deadlock, can happen in operating systems. When multiple processes block each other, deadlock occurs. The result can be major performance degradation, frozen applications, or (in extreme cases) a complete system crash.
That’s why understanding how to detect and mitigate deadlock issues is a key skill for IT engineers who help administer operating systems – as well as platforms that interact extensively with operating systems, like Kubernetes. Keep reading for guidance on how to manage operating system deadlock risks.
What is deadlock in operating systems?
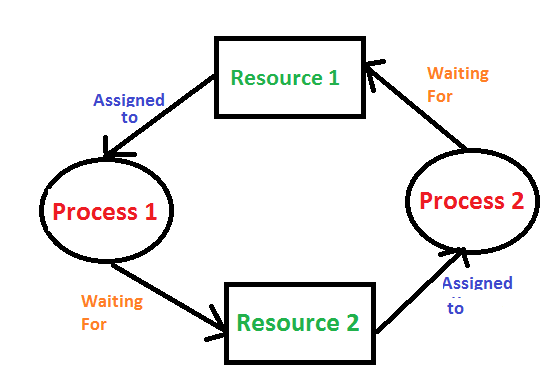
Deadlock is a state that occurs when processes within an operating system block each other, typically because each one is trying to access the same resource.
To understand fully what this means, let’s step back a bit and talk about how operating systems work. All modern, mainstream operating systems (including Windows, Linux, and macOS) use processes to manage workloads. A process is a distinct unit of work. Often, each application runs as a process, although in some cases a single application runs as multiple processes. The operating system itself also typically runs processes (usually called system processes or kernel threads) that perform management tasks on behalf of the OS.
Normally, each process operates independently of other processes. Indeed, the ability to run multiple processes simultaneously is a key capability for modern operating systems. If multiple processes need to share the same resource (for instance, if they all need to write to the same file), the operating system typically manages their access such that no one process monopolizes the resource or blocks other processes. And if one process tries to claim exclusive ownership of a resource, the operating system can forcibly release the resource via a capability known as preemption.
However, this doesn’t always work as it should. In some cases, one process might try to monopolize a resource, and for various reasons (such as the disabling of preemption in an OS’s configuration), the operating system won’t force the process to release it. If other processes are also trying to access the resource in order to proceed with their next operation, all of the processes grind to a halt, leading to what’s known as deadlock.
For deadlock to occur, four key conditions (sometimes known as the Coffman conditions, after the computer scientist who first described them in the 1970s) must be present:
- A resource must exist that is not shareable (meaning it’s impossible for multiple processes to use it at exactly the same time).
- A process must be requesting exclusive access to the resource.
- Another process must also be requesting access to the resource, creating a circular chain.
- Preemption must be disabled, preventing the OS from solving the problem by forcing the processes to release the resource.
If you’re wondering why deadlocked processes don’t resolve the issue themselves by shutting down or recalling their resource request, the answer is that this is just not how most processes work. Typically, a process will keep running indefinitely until it completes its assigned tasks – and if completing those tasks requires access to a resource that is being monopolized by another process, the first process will simply keep waiting. Hence how multiple processes can end up blocking each other indefinitely, unless the OS steps in to break the deadlock.
Deadlock prevention vs. deadlock detection
Operating systems attempt to deal with deadlock in two basic ways:
- Deadlock prevention: OSes will try to prevent deadlock from occurring in the first place. Preemption is the most obvious way for them to do this; however, even if the OS can’t preempt a process, it can endeavor to prevent deadlock through methods like requiring processes to identify which resources they need before they actually execute, allowing the OS to determine ahead of time whether the execution of a process will trigger a deadlock event.
- Deadlock detection: Operating systems include tools (like lockdep in Linux) that monitor running processes and look for signs of deadlock. The ability of the OS to recover from a deadlock condition depends mainly on whether it is able to use preemption to resolve the issue (we’ll discuss deadlock recovery in detail in a bit).
Operating system deadlock vs. other types of deadlock
Usually, deadlock refers to situations where multiple processes on the same operating system compete for a resource.
But the term can also refer to similar situations in other contexts, such as:
- Database deadlock: This occurs when multiple database transactions are trying to access the same resource (for example, when they’re trying to write data to the same location at the same time) and block each other.
- Container deadlock: In containerized applications, multiple containers may try to access the same resource, which can cause deadlock. The containers could be hosted on the same operating system, but container deadlock can also occur between containers running on different nodes within a Kubernetes cluster.
Why deadlock detection matters in distributed and cloud systems
Deadlock detection is important because deadlock can lead to major performance issues.
This is primarily because deadlocked processes continue to consume resources, even if they’re not actually “doing” anything due to the deadlock. So, a deadlock can tie up CPU and memory indefinitely, resulting in fewer resources for other workloads to use. In a distributed system like Kubernetes, deadlocks can degrade the overall performance of all applications, not just those associated with deadlocked processes.
There is also a risk that, if a deadlock goes on long enough, all system resources will become exhausted. This can cause the operating system to stop responding or to crash, which is another scenario in which the deadlock impacts not just the specific deadlocked processes, but all workloads hosted by the server.
How deadlock detection works
Different operating systems employ various tools or utilities for deadlock detection, and they each use somewhat different deadlock detection mechanisms or algorithms. In general, however, deadlock detection is usually based on the following process:
- The operating system monitors running processes and the resources that they are either using or have requested.
- If one process is requesting a resource that is currently allocated to another resource, or if multiple processes are requesting the same resource, the OS flags this as a potential deadlock.
- The OS performs additional analysis to determine whether the potential deadlock is likely to resolve itself by assessing whether viable paths exist for sequentially granting each of the processes the access they request. If not, the OS deems a deadlock to exist.
In cases where a deadlock happens, the OS can typically preempt a process (which, again, means that it forces the process to release a resource so that other processes can use it). It may also forcibly terminate processes as a way of preventing a crash.
Deadlock detection methods and algorithms
To be more specific about how deadlock detection works, here’s a look at common types of deadlock detection methods or algorithms.
Wait-for-Graph algorithm
A Wait-for-Graph (WFG) algorithm maps the relationship between processes and resources to construct a graph that represents the state of system resource allocations. By assessing this graph, the OS can identify circular cycles in which multiple processes are requesting the same resource, creating a deadlock condition.
WFG is one of the simplest deadlock detection algorithms, but it only works in scenarios where each resource type has one unique instance. It doesn’t work well if the same resource can have multiple instances (which could happen if, for example, virtual memory resources are abstracted from physical memory such that the OS could create multiple instances of the same memory resource).
Matrix-based detection algorithms
A more sophisticated means of detecting deadlocks is matrix-based algorithms. These create a matrix that displays available instances of each resource type, resource requests, and resource allocations. Because matrix-based algorithms can represent multiple resource instances, they can support environments where resources are not limited to a single instance.
Chandy-Misra-Haas model
The Chandy-Misra-Haas model takes a different approach to deadlock detection: Rather than graphing relationships between processes and resources, it uses probes to trace resource allocations in real time. If a probe reveals that a process can’t access a requested resource because it is being monopolized by another resource, the model flags the condition as a deadlock event.
Chandy-Misra-Haas algorithms tend to be more effective at deadlock detection in complex, distributed systems, where real-time probing is more likely to capture resource allocations accurately than graphing.
Deadlock recovery strategies
An operating system’s response to deadlock conditions can vary depending on which capabilities it has and how it is configured. Here are the main recovery strategies that OSes will pursue in most cases.
Preemption
Preemption gives operating systems the ability to interrupt a process (which means the process pauses, forcing it to release any resources it is currently using). Preemption is the most straightforward and least disruptive way to recover from a deadlock. It doesn’t disrupt processes permanently; it just pauses them so another process can access resources.
So, why don’t OSes always resolve deadlock using preemption? The answer is that operating system configurations may prevent preemption. For instance, when you compile a Linux kernel, you can set options like PREEMPT_NONE, which tells the OS never to preempt a kernel-level process. Turning off preemption can lead to better operating system stability.
Process termination
Another deadlock solution is to terminate one or more deadlocked processes. This resolves a deadlock, but the obvious downside is that processes will stop, so any applications that depend on those processes will crash.
Rollback
As an alternative to preemption and process termination, an OS may roll back a deadlocked process to a previous state. To do this, the OS must track process states continuously and have a reversion mechanism in place that allows it to roll processes back to a state known to be stable.
Rollback capabilities are not a native feature of most operating systems, but you can install them using add-on tools like Checkpoint/Restore in Userspace (CRIU), which implements process rollback for Linux.
Challenges in deadlock detection across modern systems
At first glance, deadlock detection may seem simple enough. Detecting when multiple processes are trying to monopolize the same resource may not appear to be rocket science.
In reality, though, deadlock detection isn’t always simple or straightforward due to challenges like the following:
- False positives: An OS might incorrectly flag processes as being deadlocked. This most often happens when the processes would share a resource appropriately if given enough time; however, the OS doesn’t have a way of knowing how long each process will tie up the source, so it mistakenly thinks a deadlock event has occurred.
- Different process types: System-level processes (meaning those executed by the operating system itself) often vary in behavior from userspace processes (like those started by applications). As a result, the effectiveness of deadlock detection algorithms can also vary for each category of process.
- Constant change: Modern operating systems are highly dynamic, with processes constantly spinning up and down, and resource allocations always changing. Under these conditions, it can be tough to determine when a persistent deadlock has occurred.
- Overhead: Running deadlock checks consumes resources, which means that if the OS is too aggressive about trying to detect deadlocks, it can degrade overall performance (due to the resources expended on the deadlock checks) even if no deadlocks exist.
Best practices for reliable deadlock detection
There is no “one dumb trick” for quickly and accurately detecting deadlocks in all cases. However, the following best practices can help to streamline reliable deadlock detection:
- Deploy stable applications: Unstable or poorly coded applications are a frequent root cause of deadlocks. For that reason, choosing to deploy stable, well-tested apps is a first step toward reliable deadlock detection. This reduces the number of deadlock conditions you need to handle in the first place.
- Perform load-testing: Load-testing operating systems by deploying a large number of processes on them in a testing environment can also help build confidence about deadlock detection. When you know how your OS behaves under heavy load, you gain more visibility into the types of issues that are likely to cause a deadlock.
- Use multiple detection mechanisms: Since the accuracy of deadlock detection tools and models can vary, consider employing multiple algorithms at the same time and comparing their results before concluding that a deadlock is present.
How groundcover enhances deadlock detection and recovery
By providing continuous, end-to-end visibility into the state of all processes and resources on all servers within a cluster, groundcover helps engineers detect and respond to deadlock events quickly and accurately. When it comes to deadlocks, context is everything – and it’s only by seeing the status of all processes and resource allocations that you can reliably determine whether a deadlock is indeed happening, then make an informed decision about how to proceed.
.png)
Operating system tools and utilities can help you detect likely deadlock events, but only observability solutions like groundcover provide the insight you need to confirm deadlocks and react appropriately.
Don’t let deadlock get you down
Deadlocks, like traffic jams, are an unavoidable fact of life. But that doesn’t mean they have to lead to major disruptions. With the right deadlock detection tools and strategies, you can accurately identify and respond to deadlocked processes in ways that minimize disruptions and maximize overall system performance.
FAQ
What causes deadlocks in distributed and containerized environments?
In distributed, containerized environments, deadlocks most often occur when multiple processes are trying to access the same resource, and the resource is not shareable. In some cases, all processes run on the same node; however, it can also happen that containers on different nodes will try to access the same resource (like a file), leading to cross-node deadlocks.
How can real-time observability tools improve deadlock detection accuracy?
Observability tools improve deadlock detection and accuracy by providing context about the processes and resources associated with deadlocks. For example, analysis of deadlock patterns from across a distributed environment can help to identify conditions that most often lead to deadlocks for particular types of processes or resources.
How does groundcover help teams identify and resolve deadlocks faster?
As an end-to-end observability platform, groundcover delivers the comprehensive context necessary to confirm and mitigate deadlocks quickly. It provides more detail about the state of resources than deadlock detection tools can supply on their own.













.svg)