Kubernetes CPU Limits Explained: Configuration, Impact & Best Practices


In many respects, CPU is the most precious type of resource in a Kubernetes cluster – and when applications use too much of it, bad things can happen. Fortunately, there’s a way to prevent overuse of CPU: The Kubernetes CPU limits feature. By setting CPU limits, you can mitigate the risk that a container will consume more than its fair share of CPU resources, which can, in turn, help to improve the overall performance of Kubernetes workloads.
That said, CPU limits in Kubernetes can also be tricky to work with because limits that are too low can negatively impact application performance. If you starve your containers of resources by granting them insufficient CPU, you’re going to have problems.
How can Kubernetes admins navigate the strait between too much and too little CPU? Read on for guidance as we explain everything you need to know about using, configuring, and managing CPU limits.
What are CPU limits in Kubernetes?
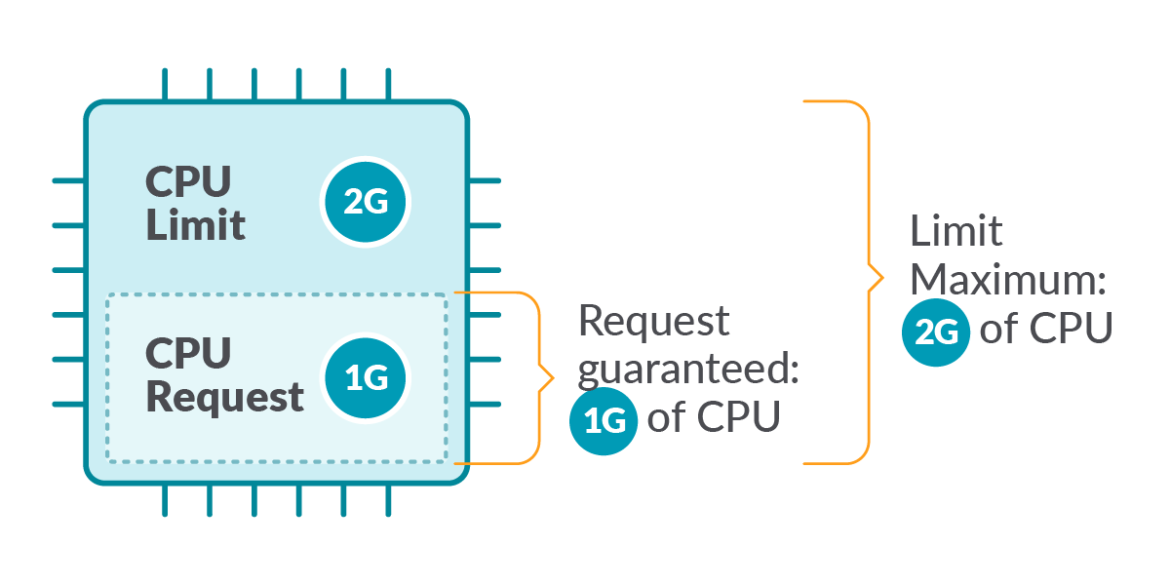
CPU limits in Kubernetes are an optional setting that restricts how many CPU resources a container or Pod can use (support for CPU limits for Pods is only available starting with Kubernetes version 1.34).
To understand fully what CPU limits mean, let’s step back and talk about CPU resources. CPU (also sometimes called compute) is the type of resource that applications use to process information. An application requires CPU to operate, and the exact amount of CPU that an application uses can fluctuate over time. When an app is receiving a lot of requests or is processing complex requests, its CPU usage usually increases.
CPU limits are a way of preventing a Kubernetes workload (or a part of that workload) from using more than a certain amount of CPU. As we’ll explain in more detail below, setting this type of limit is useful because it helps prevent situations where one application “hogs” all of the CPU available on a node in a way that prevents other applications from functioning normally.
You don’t have to assign CPU limits. Kubernetes will allow workloads without a limit specification to consume as much CPU as they want, up to whatever maximum amount is available.
Kubernetes CPU requests vs. CPU limits
Kubernetes also provides a CPU requests feature. CPU requests specify the minimum amount of CPU resources that should be available to a container. The actual CPU capacity accessible to the container can exceed the request.
So, while CPU requests and limits in Kubernetes both deal with the way Kubernetes allocates CPU resources to workloads, they address different needs. CPU limits place a ceiling on how much CPU a container or Pod can use, while CPU requests set a floor.
How CPU limits work in Kubernetes
CPU limits work based on the following steps.
1. Admins set CPU limits
First, admins specify a CPU limit when configuring a container or Pod by including the limit within the resource’s spec. For example, the following code sets a limit of 500 millicores (represented as 500m):
2. Kubernetes restricts CPU access
Once a limit is set, Kubernetes automatically enforces it using the cgroups feature in the Linux kernel, which makes it possible to allocate specific amounts of resources to individual processes.
The amount of CPU that Kubernetes allows a container or Pod to use reflects how many cores or millicores the admin configured. A core is equivalent to one physical or virtual CPU core, and millicores are fractions of a core (500 millicores is half a core, for example). A workload that receives a CPU limit of 1 core would be prevented from consuming the compute capacity provided by more than 1 CPU core.
If a container or Pod tries to use more CPU than its limit, Kubernetes will throttle CPU availability by reducing the CPU available to the workload. Throttling can result in a container or Pod pausing or slowing down.
3. Admins modify CPU limits
If desired, you can change a CPU limit for an existing workload (or add a limit for a workload that doesn’t currently have one) by modifying the workload’s YAML configuration code, then reapplying the updated code with kubectl.
Note, however, that the change won’t take effect until Kubernetes recreates the impacted containers or Pods (and whether it recreates them automatically depends on which type of deployment strategy you chose when you initially created the workload).
The role of CPU limits in resource management
CPU limits are an important part of Kubernetes resource management because they help prevent containers or Pods from becoming “noisy neighbors” that use too much CPU, depriving other workloads of the CPU resources they need to perform adequately.
Now, you may be thinking, “Won’t Kubernetes reschedule containers on a different node if there’s not enough CPU to go around?” The answer is that it certainly will try to reschedule containers (which means moving them to a different node, or host server) if other containers are sucking up all of the CPU on a given node. The problem, though, is that there may not be other nodes available with spare CPU. It may also be the case that containers can’t be rescheduled because admins configured them to run on a specific node. Plus, even if rescheduling is successful, workload availability may be disrupted while a container moves to a new node. So, your goal as a Kubernetes admin should be to avoid scenarios where containers or Pods run short of CPU resources. CPU limits help to do this.
It’s also worth noting that if you’re thinking that you don’t need CPU limits because you’ve taken care to ensure that your cluster is large enough to support all of your workloads without running out of CPU, keep in mind that containers could unexpectedly experience a surge in CPU due to issues like buggy code. Having CPU limits in place helps prevent problems like these from affecting other workloads due to exhaustion of all available CPU resources.
How to configure CPU requests and limits
The most common way to set a CPU request or limit is to include it in a workload’s container spec. For example, the following code sets a limit of 2 cores and a request of 1 core for the container named some-container:
It’s also possible, starting with Kubernetes version 1.34, to set limits and requests for entire Pods, as opposed to individual containers within a Pod. To do this, you include the limit or request in the Pod spec, such as in this example:
In this case, the entire Pod (meaning all containers running in it) can’t use a total of more than 1 CPU core.
To use Pod-level requests and limits, you need to enable the PodLevelResources feature gate in Kubernetes, since the feature is currently still in beta.
Performance impact of CPU limits in Kubernetes
The goal of admins in setting CPU limits is usually to achieve better overall performance. Whether they succeed depends on whether they choose effective limits.
If limits are too low, there is a risk that workloads will fail to perform adequately because they need more CPU than the amount allocated to them. This can be especially problematic for workloads that require low latency, since latency requests typically increase when there’s not enough CPU.
The best way to know whether your CPU limits are effective is to monitor the actual performance of your workloads. If you detect frequent CPU throttling events, it may mean that your limits are too low.
Common issues with CPU limits
While CPU limits can be a powerful way to help manage CPU resources, they can also present some challenges.
Overly restrictive limits degrading performance
The most common problem with CPU limits in Kubernetes is setting limits too low. As we’ve explained, limits that are too restrictive can prevent workloads from performing adequately because they won‘t have enough CPU.
Risk of wasted resources
In addition to undercutting workload performance, limits that are too low can prevent applications from making efficient use of available CPU resources. This can happen if there is spare CPU available within the cluster, but no applications can use it because they’ve already hit their limits.
Consider, for instance, a batch-processing workload. The more CPU available to it, the faster it will complete processing. But if limits prevent it from making use of CPU cores that are sitting idle, the workload will take longer to complete its task, for no good reason.
Variability in the compute power of CPU cores
Another challenge is the fact that the amount of compute capacity associated with a single core can vary significantly. Kubernetes treats CPU cores as universal units. This means that if you limit a workload to, say, 1 core, Kubernetes will prevent the workload from using more than 1 core, no matter which node is hosting it.
This can become problematic in clusters where the type of CPU running on nodes varies. The total amount of computing power provided by a single core depends on factors like processor architecture and clock speed, which means that 1 core worth of CPU on one node might provide more or less compute power than 1 core on a different node would. Kubernetes’s CPU limit feature doesn’t account for this.
Best practices for optimizing CPU limits in Kubernetes
To use the CPU limit feature effectively without causing more problems than it solves, consider the following best practices:
- Don’t be overly restrictive: The most important rule of CPU limits is to avoid making them too low. Set limits that will prevent runaway CPU usage due to issues like buggy code, while still providing enough CPU to accommodate unexpected spikes in demand.
- Set requests alongside limits: Setting both requests and limits helps to provide a balanced approach to resource management in Kubernetes. If you set limits alone, Kubernetes has no way of knowing how much minimum CPU to assign to each container, making it harder to distribute CPU efficiently.
- Provide adequate CPU resources: The more CPU you have available in your Kubernetes cluster, the less you have to worry about setting overly restrictive CPU limits.
- Maintain consistent processors: If possible, choose nodes with identical or similar processors. This helps ensure that 1 core worth of CPU will represent a consistent amount of compute capacity, no matter which node is hosting a workload.
- Consider Pod-level resource limits: In some cases, Pod-level limits can be more effective than container-level limits. It’s often easier to predict the overall resource needs of an entire Pod (which is typically equivalent to a discrete workload) than it is to predict the resource needs of individual containers within the Pod. The exception to this rule is if you’re worried about individual containers within a Pod starving other containers in the same Pod of resources, in which case container-level limits are more appropriate.
Monitoring and debugging CPU limits in Kubernetes
Kubernetes doesn’t include much in the way of native functionality for monitoring and debugging CPU limits. You can, however, use a list of the limits currently set for each container using a command like the following:
This lists Pod details and filters information related to limits.
Checking for CPU throttling events can also be useful for monitoring CPU limits and their impact on your cluster. There’s no way to detect throttling events directly in Kubernetes, but you can find this information by logging into nodes and checking the cpu.stat files for each Pod. These files are usually located at /sys/fs/cgroup/cpu,cpuacct/kubepods/burstable/<pod_cgroup_id> (although this can vary depending on your Linux distribution). The files contain data about the number of times each container’s CPU was throttled and how long the throttling lasted.
To monitor and debug CPU limits at scale, consider using an external monitoring and observability platform that can automatically monitor CPU usage and throttling events by pulling metrics from Kubernetes. That way, you get continuous visibility into actual CPU usage and situations where workloads are being deprived of CPU.
How groundcover optimizes CPU limits and performance visibility
Speaking of observability platforms that deliver continuous, automated visibility into CPU limits and workload performance, let’s talk about groundcover.
.png)
When you use groundcover, not only do you get an automated way of monitoring CPU usage and throttling, but you can also get complete contextual information – such as what was happening before and after a throttling event or how each container’s request rate correlates with CPU usage. This visibility is critical for making informed decisions about which limits to set and modifying limits once they are in place.
Taking advantage of CPU limits – within limits
CPU limits are a powerful feature in Kubernetes, but they have their limits. Due to challenges like the inability of knowing exactly how much CPU power a given core will provide, and the risk of starving workloads of adequate resources due to limits that are too low, it’s important to use limits strategically, and to accompany them with requests where possible as a way of balancing CPU allocation in Kubernetes. Just as important is monitoring actual CPU usage so you know when workloads are running low on compute.
FAQ
What’s the impact of setting CPU limits too low in Kubernetes?
Limits that are too low can degrade the performance of the workload to which they apply. This is because Kubernetes will prohibit containers or Pods from using more CPU than the amount granted by a CPU limit – and if the limit is too low to meet the workload’s requirements, the workload won’t have sufficient processing power to operate normally.
How can I monitor CPU throttling and identify misconfigured Pods?
It’s possible to check the cpu.stat files on Kubernetes nodes to identify CPU throttling events, as explained above. A more efficient approach for monitoring CPU throttling, however, is to use an automated monitoring and observability solution, like groundcover, that will identify throttling events without requiring you to log into each node. It will also show you which containers and Pods are impacted by CPU availability issues so that you can reconfigure them as needed.
How does groundcover help detect and resolve CPU throttling in real time?
With groundcover, you get continuous visibility into the actual CPU consumption of all of your workloads. You also benefit from contextual data that shows you how different types of events (like Pod rescheduling or a surge in a certain type of request) correlate with CPU availability and throttling. This insight helps you to make informed decisions about how much compute to grant to each container or Pod.













.svg)