Circuit Breaker Pattern: How It Works, Benefits & Best Practices



Distributed systems fail. A database slows down, an API times out, a service crashes. When one service fails in a microservices architecture, it can take down everything else that depends on it. According to research published in the International Journal of Scientific Research, circuit-breaking patterns reduce cascading failures by 83.5% in production environments. That's the difference between a single service outage and a complete system meltdown.
The circuit breaker pattern stops these cascading failures before they happen. Like an electrical circuit breaker that cuts power when it detects an overload, the software circuit breaker pattern stops your application from repeatedly calling a service that's already failing. Instead of wasting threads and connections on doomed requests, the circuit breaker fails fast and gives the struggling service time to recover.
This article explains how the circuit breaker pattern works, why it's important in microservices architectures, and how to use it correctly in production. You'll learn the main states, failure thresholds, common mistakes, and best practices that stop one service from failing and bringing down your whole system.
What Is Circuit Breaker Pattern?
The circuit breaker pattern wraps calls to remote services in a monitoring object that tracks failures. When failures hit a threshold, the circuit breaker trips. It stops sending requests to the failing service and returns errors immediately. After a timeout period, it allows a few test requests through to see if the service has recovered.
This pattern originated in Michael Nygard's book "Release It!" and was popularized by Martin Fowler's description. Think of it like an electrical circuit breaker in your house, that when too much current flows through the circuit, the breaker trips and cuts power. The software version works the same way, but with failed service calls instead of electrical current.
Core Concepts Behind the Circuit Breaker Pattern
The circuit breaker pattern relies on a few key principles:
- Failure Detection: The circuit breaker monitors every call, counting successes and failures. It looks for patterns like increased error rates or slow responses that indicate problems.
- Fast Failure: When the circuit trips open, it fails immediately without calling the struggling service. This prevents your application from waiting on timeouts that burn through threads and connections.
- Self-Healing: Circuit breakers automatically attempt recovery after a timeout period. Once the timer expires, the circuit switches to half-open and tests whether the service has recovered.
- Fallback Mechanisms: Instead of just returning errors, you can serve cached data, default values, or degraded functionality that keeps your application partially working.
- Resource Protection: By preventing calls to failing services, circuit breakers protect your application's resources. Threads don't pile up waiting for timeouts, and connection pools don't get exhausted.

How the Circuit Breaker Pattern Works in Microservices
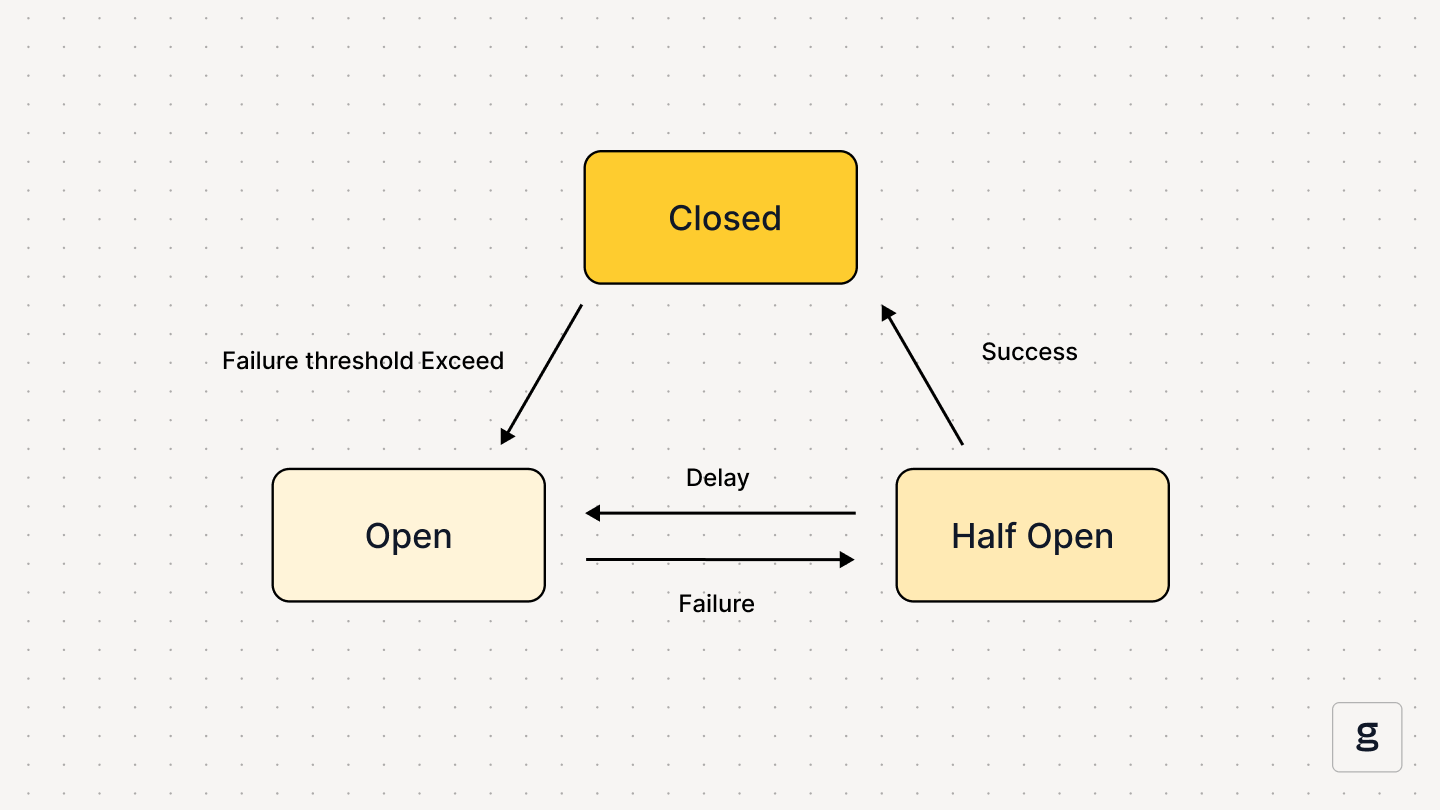
The circuit breaker operates in three states, transitioning between them based on the health of the remote service.
1. Closed State
In the closed state, the circuit breaker allows all requests through to the remote service. This is normal operation. The circuit breaker tracks calls, maintaining a counter of recent failures. When the failure count exceeds your configured threshold, like five consecutive failures or 30% of calls failing, the circuit breaker trips open.
2. Open State
When the circuit breaker trips into the open state, it stops calling the remote service entirely. Every request fails immediately without making actual network calls. This protects your system from wasting resources and gives the struggling service breathing room to recover. The circuit breaker stays open for a configured timeout period, usually 30 seconds to a few minutes, and then transitions to half-open.
3. Half-Open State
The half-open state is the testing phase. The circuit breaker allows a limited number of requests through, which is often just one or a few test calls. If these succeed, the circuit closes and normal operation resumes. If they fail, the circuit trips back to open immediately and resets the timeout timer.
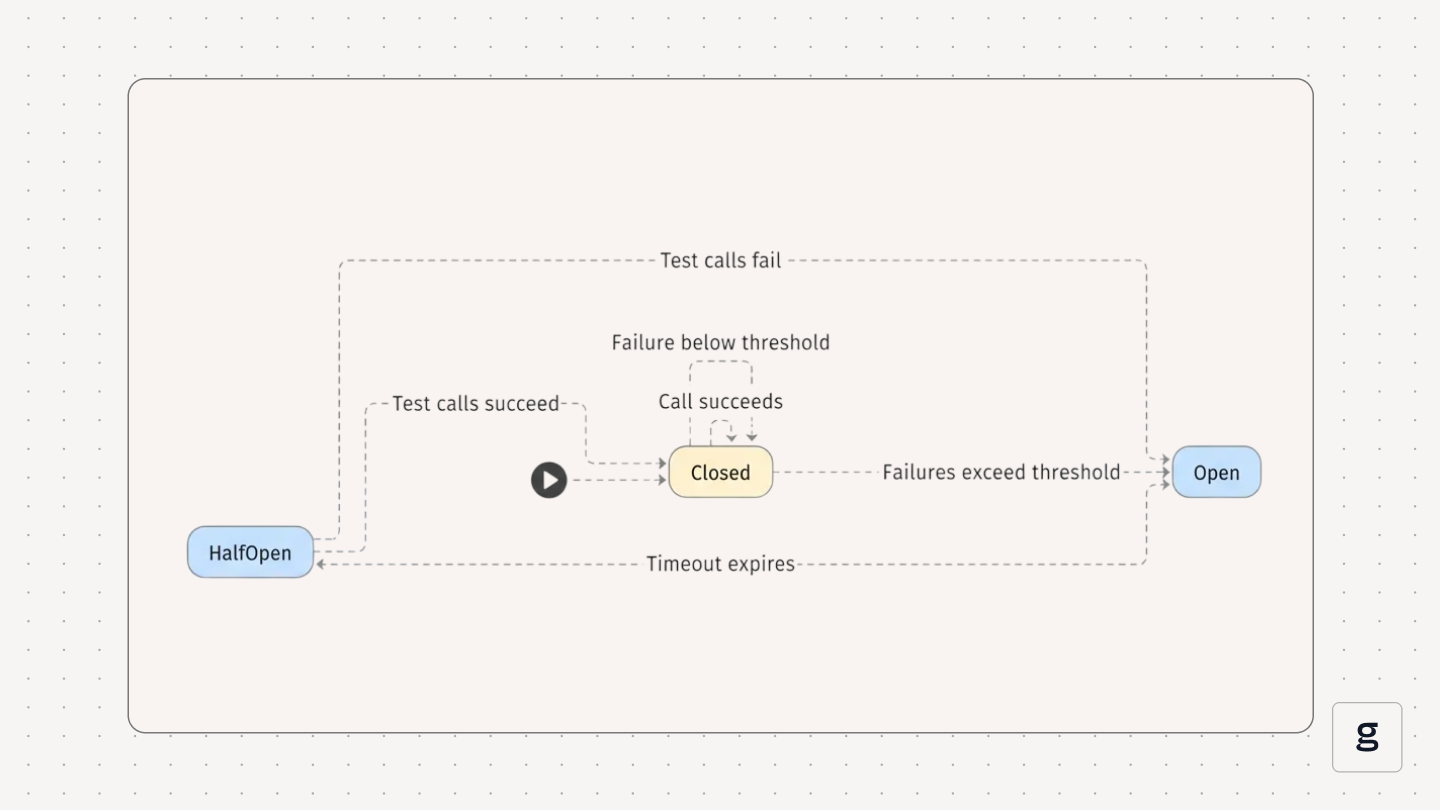
4. State Transitions and Failure Thresholds
State transitions depend on your configuration. A simple circuit breaker might trip after five consecutive failures and close after three consecutive successes. More sophisticated implementations use sliding windows (tracking failure rates over the last N seconds or N calls).
Here's what the state machine looks like:
Benefits of Using the Circuit Breaker Pattern
Challenges and Pitfalls of the Circuit Breaker Pattern
Circuit breakers solve problems but create new ones. Here's what goes wrong:
Best Practices for the Circuit Breaker Pattern
Getting circuit breakers right requires following patterns that work in production:
- Start with Conservative Thresholds: Better to trip too early than too late. A good starting point is 5 failures in 10 seconds with a 30-second timeout.
- Implement Proper Fallbacks: Don't just return errors. Serve cached data, default values, or degraded functionality. A search service might return popular results from cache instead of nothing.
- Monitor Circuit Breaker State Changes: Every trip and reset should be logged and tracked. Frequent state changes indicate misconfiguration or underlying service problems.
- Set Appropriate Timeouts: Profile your service calls to understand normal latency. Set timeouts that catch truly hung calls without killing slow-but-working requests.
- Use Different Breakers for Different Operations: Don't wrap all calls to a service in one circuit breaker. Separate breakers for read vs write operations keep granular control.
- Test Failure Scenarios Regularly: Chaos engineering isn't optional. Deliberately trip circuit breakers in test environments to verify your fallbacks work.
When to Use the Circuit Breaker Pattern
Circuit breakers make sense in specific scenarios:
- Remote Service Calls with Variable Reliability: External APIs, third-party services, microservices you don't control
- High-Traffic Systems Where Failures Cascade: E-commerce checkouts, payment processing, user authentication flows
- Services with Expensive Operations: Database queries, ML model inference, heavy computations that shouldn't retry endlessly
- Systems with Strict SLAs: When you need predictable failure behavior
- Microservices Architectures with Deep Dependencies: Where one failing service can take down multiple dependent services
When NOT to Use: Simple, reliable internal calls; operations that must complete (financial transactions); low-traffic systems where complexity outweighs benefits.
Steps to Implement the Circuit Breaker Pattern
1. Define Error Thresholds and Timers
Start by deciding when your circuit breaker should trip. You need three numbers: failure threshold (5 failures in 10 seconds), timeout duration (30 seconds), and success threshold (three consecutive successes). These numbers depend entirely on your service characteristics.
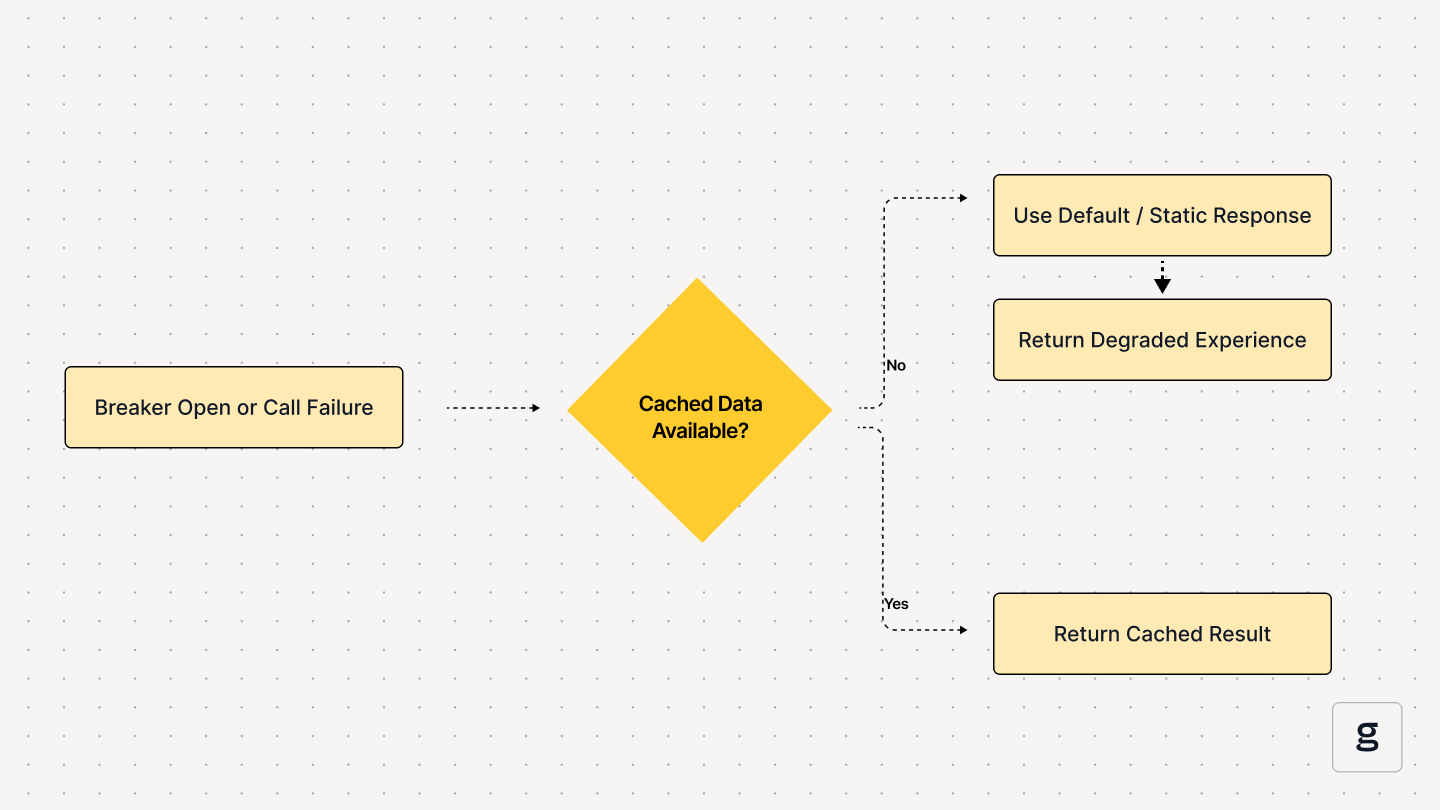
2. Build Fallback or Degraded Workflows
Circuit breakers need fallback logic. Options include cached responses, default values, simplified functionality, or honest error messages.
Here's a simple implementation:
3. Configure Monitoring and Alerts
Track circuit state, trip count, open duration, fallback usage, and success/failure rates. Alert on circuits that trip frequently, stay open for extended periods, or show sudden changes in trip frequency.
4. Test Recovery and Failure Scenarios
Don't wait for production to validate your circuit breakers. Test them with chaos testing, load testing with injected failures, and recovery testing. Here's a complete Spring Cloud Circuit Breaker implementation:
Tools and Frameworks That Support the Circuit Breaker Pattern
Most production systems use a library rather than building from scratch. For Spring applications, Spring Cloud Circuit Breaker provides a unified abstraction. Start with Resilience4j as the backing implementation.
Observability Requirements for the Circuit Breaker Pattern
You can't manage circuit breakers without visibility into what they're doing.
Essential Metrics: Circuit breaker state per service, trip frequency and duration, fallback invocation rate, request success/failure rates, latency percentiles, error types causing trips.
What to Alert On: Frequent state changes (flapping), extended open state duration, high fallback usage, and unusual error patterns.
How groundcover Enhances the Circuit Breaker Pattern
Observing circuit breakers across a distributed system is hard. Each service instance has its own circuit breakers, and correlating breaker state with system health requires gathering metrics from everywhere. groundcover makes this manageable.
- Real-Time Circuit Breaker State Tracking: Visualize circuit breaker state across all services in one unified view. See which circuits are open, how long they've been open, and which services are affected.
- Automatic Anomaly Detection: Identifies misconfigured circuit breakers or unusual trip patterns automatically. If a circuit is tripping far more often than others, you'll know immediately.
- Low-Overhead eBPF Monitoring: Collects detailed circuit breaker metrics with minimal overhead using eBPF, which is critical when dealing with performance-sensitive services.
- Correlation with System Events: Links breaker trips to underlying infrastructure issues (network problems, container restarts, resource exhaustion). You see why a circuit tripped, not just that it did.
- Distributed Tracing Integration: See how circuit breaker behavior affects entire request flows. Trace visualization shows the impact on dependent services and user-facing requests.
Conclusion
The circuit breaker pattern prevents cascading failures that can take down entire distributed systems. By monitoring service health and failing fast when services struggle, circuit breakers protect your application's resources and give failing services time to recover. The pattern isn't complicated. Just three states, a few thresholds, some fallback logic, but the operational impact is huge.
Start with one critical service dependency. Configure conservative thresholds. Implement meaningful fallbacks. Monitor state changes closely. Test failure scenarios deliberately. Circuit breakers aren't a silver bullet, but they will prevent one failing service from destroying everything else. In distributed systems where failures are inevitable, that's the difference between an incident and an outage.
FAQs
How do circuit breaker metrics help teams diagnose performance or latency issues?
Circuit breaker metrics provide crucial context that raw request data misses, offering precise signals about service health and recovery:
- Service Instability: Trip frequency correlates directly with underlying service instability.
- Recovery Duration: Open duration indicates exactly how long the struggling service takes to recover.
- User Impact: Fallback usage shows the scope of user requests impacted by the failure (relying on degraded functionality).
- Contextualizing Problems: The circuit breaker's state helps diagnose the problem type. If latency is high but the circuit is not tripping, the issue is generalized slowness, not a complete functional failure.
- Defining Timelines: State transitions (Closed; Open; Half-Open; Closed) define the precise start and end points of a service interruption, aiding investigation.
What's the difference between the circuit breaker pattern and the retry or bulkhead patterns?
- Circuit breaker stops calling a failing service entirely after hitting a threshold. It prevents wasting resources on requests that will probably fail.
- Retry pattern automatically retries failed requests with exponential backoff. It handles transient failures.
- Bulkhead pattern isolates resources like thread pools so one failing dependency can't exhaust all resources. In practice, you use all three together.
Circuit breakers prevent retries to dead services. Bulkheads prevent circuit breaker failures from exhausting resources. Retries handle transient failures before the circuit breaker notices.
How does groundcover help teams detect misconfigured or frequently tripping circuit breakers in production?
groundcover analyzes circuit breaker behavior patterns across your entire system. It compares trip rates, open durations, and state transition frequencies between different services to identify outliers.
- The platform correlates circuit breaker metrics with infrastructure events and resource usage.
- When a circuit trips, groundcover shows you what else was happening, like CPU spiking, high network latency, or containers restarting.
- For misconfiguration specifically, groundcover flags circuits with suspicious patterns: thresholds too sensitive (constant flapping), timeouts too short, or success criteria too aggressive.













.svg)