ReplicaSet vs Deployment: Kubernetes Differences Explained



If you want to deploy containers in Kubernetes, two of the options for doing so are to create a ReplicaSets or a Deployment. However, while both of these resources will run Pods for you, they do so in different ways. Deployments are a more open-ended, flexible approach to deploying an application, whereas ReplicaSets are designed for the more specific use case of deploying multiple copies (or replicas) of a Pod.
In a nutshell, that summarizes the main difference between Deployments and ReplicaSets. But there’s much more to say on the topic. Read on for full details as we compare and contrast Deployments and ReplicaSets, show how to create each one, and explain what to use when.
Understanding ReplicaSets in Kubernetes
A ReplicaSet is a type of object that tells the Kubernetes deployment controller to maintain a specific number of copies of a Pod (for full details on how this works, check out our guide to ReplicaSets).
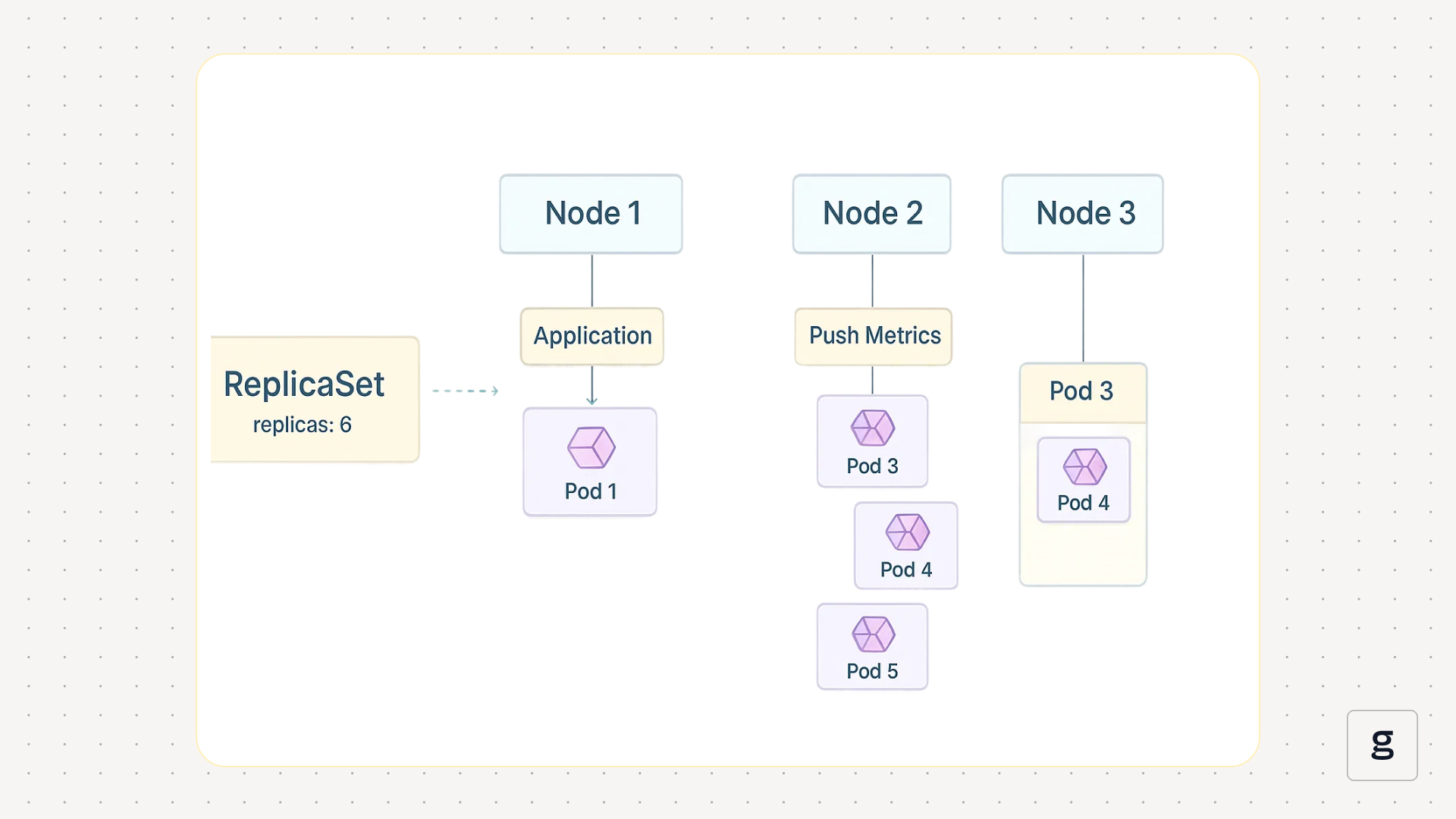
The main purpose of ReplicaSets is to support use cases that require high availability or high levels of performance. By operating multiple Pod replicas, you reduce the risk that an application will experience downtime or a performance degradation (such as a spike in latency) in response to a Pod failure. If one Pod goes down, the application will remain available and (hopefully) capable of handling its load so long as other replicas are still running (and assuming that you properly configured a Kubernetes Service capable of rerouting traffic automatically when a replica fails).
Understanding Deployments in Kubernetes
A Kubernetes Deployment is an object that tells Kubernetes to run one or more Pods. Deployments (which we cover in detail in this guide) are the most flexible way to deploy Pods in the sense that they support a wide array of configuration options and deployment modes.
For this reason, Deployments are effectively the de facto approach to running an application in Kubernetes. Unless your app has special requirements (like a persistent identity, in which case a StatefulSet is more appropriate), you’d typically default to using a Deployment.
ReplicaSet vs. Deployment: Key differences
At a high level, the main difference between a ReplicaSet and a Deployment can be summed up as follows: ReplicaSets maintain a specific number of copies of each Pod, whereas Deployments maintain only one instance of each Pod by default.
But the story is a little more nuanced than that because ReplicaSets are usually part of Deployments. In other words, to create a ReplicaSet, you’d typically create a Deployment and include a ReplicaSet within it. You’d do this by including a replicas parameter following the Deployment metadata and before the Pod template. Here’s an example:
To make matters somewhat confusing, it’s also possible to create a standalone ReplicaSet that is not part of a Deployment. You do this by creating a YAML file where the field preceding the ReplicaSet metadata identifies the object type as a ReplicaSet. For example:
However, creating separate ReplicaSets is not a common practice. Deployments provide additional configuration options (like automated rollbacks and granular control over Pod deployment process and update processes) that aren’t supported by ReplicaSets – so you’d usually want to create a ReplicaSet and manage it within a Deployment, rather than operating a ReplicaSet all on its own.
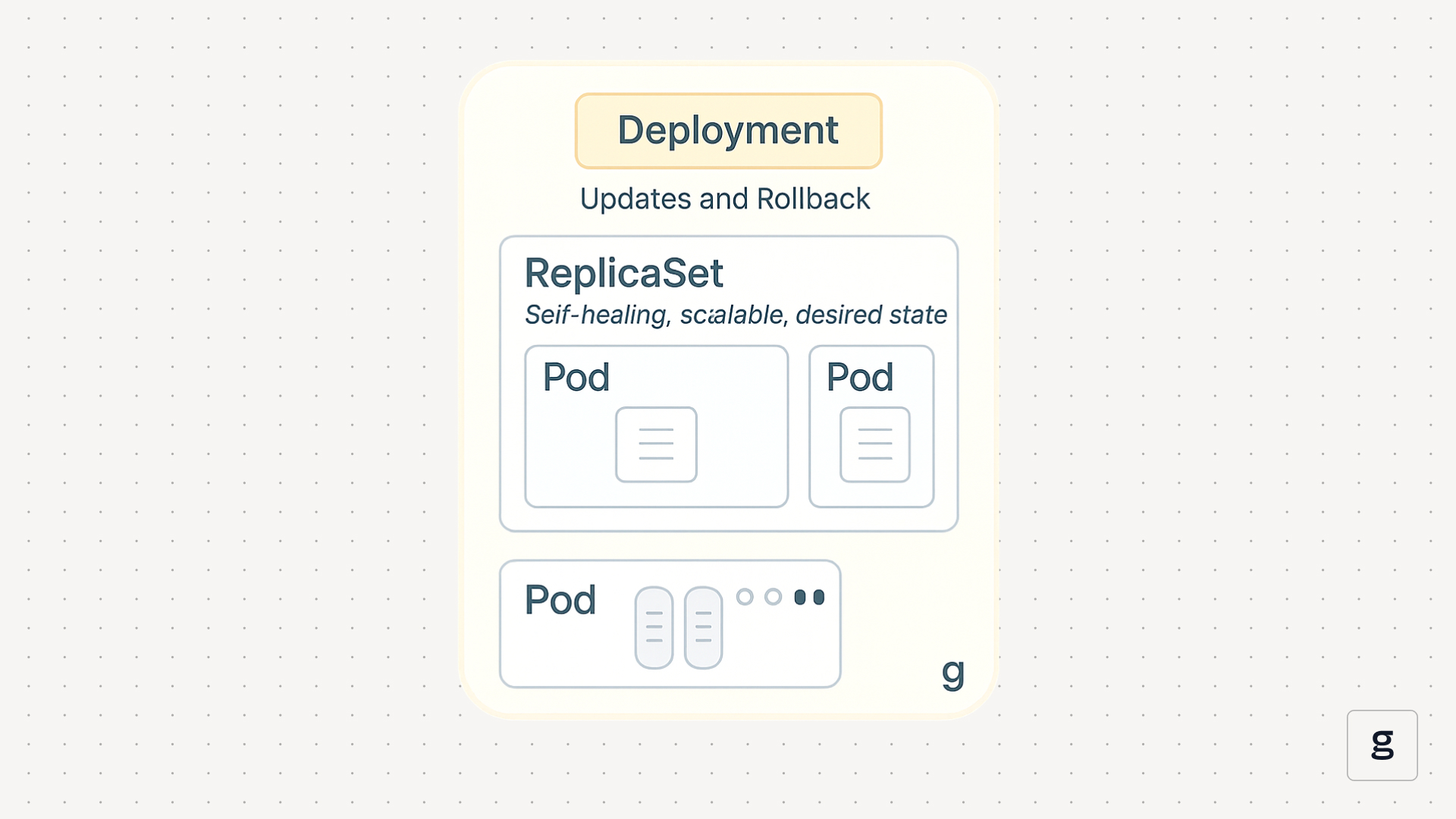
The following table summarizes the differences between ReplicaSets and Deployments in detail.
When to choose ReplicaSet vs. Deployment: Use cases and other considerations
Setting aside the nuance that ReplicaSets can be part of Deployments and therefore are not exactly an “opposite” type of object, it’s important for Kubernetes admins to understand when to create a ReplicaSet (meaning a workload with a specified number of replicas, whether it’s part of a Deployment or a separate ReplicaSet) and when to stick with a simple Deployment that doesn’t include replicas.
The main answer is to assess your application requirements and use case:
- If your app doesn’t require high availability or high levels of performance - if, for example, it’s an application that’s currently just in testing mode - a simple Deployment is best.
- In contrast, creating Pod replicas makes more sense for apps that require high availability or where you can’t tolerate performance problems.
But that’s not all. You should also think about:
- Whether you want to take advantage of Kubernetes features like rolling update strategies or automated rollbacks. As we mentioned, these are only available through Deployments (although you can use them in conjunction with a ReplicaSet if the ReplicaSet is part of a Deployment).
- Application resource requirements and your cluster’s overall resource availability. Creating Pod replicas via a ReplicaSet will increase the overall CPU and memory utilization of your workloads. If you don’t have a lot of resources to spare, ReplicaSets may be risky because they could lead to situations where Pods can’t be scheduled (meaning no nodes with sufficient resources are available to host them), or where serious performance degradations occur, due to the exhaustion of available cluster resources.
Finally, keep in mind that neither a ReplicaSet nor a Deployment may be what you need, depending on your use case. If you need to run a stateful app, a StatefulSet is better. If you need to run copies of a Pod on specific nodes in your cluster, a DaemonSet is better (unlike ReplicaSets, DaemonSets give you control over which nodes host replica Pods).
How ReplicaSets and Deployments work together
We already said that ReplicaSets can be part of Deployments, but we want to drive home this point because creating a ReplicaSet within a Deployment is really the optimal way to go. By combining ReplicaSets and Deployments, you get the best of both worlds: You can scale your applications and improve performance with replicas, while still enjoying the capabilities that Deployments provide.
Again, the way to combine ReplicaSets and Deployments is straightforward. You simply create a Deployment and define a replica count within it, like this:
Under the hood, ReplicaSets and Deployments work because the Deployment defines the desired state that your application should have. If that desired state includes a set of Pod replicas (in other words, if it includes a ReplicaSet), Kubernetes will automatically create the replicas (assuming you have enough nodes and resources to support them).
Challenges and pitfalls in using ReplicaSets and Deployments
While combining ReplicaSets and Deployments is a powerful way to improve application performance and manageability, there are some potential drawbacks:
- No guarantee of replicas: You can tell Kubernetes to create replicas. But if there aren’t enough resources in your cluster to run however many Pod replicas you ask for, it won’t be able to schedule them. In other words, just because you define a ReplicaSet within a Deployment doesn’t mean your deployed application is fully guaranteed to include replicas.
- Load balancing challenges: Replicas are only effective if you are able to balance load across them. You’d typically do this by creating a Service that distributes traffic to each of the Pod replicas associated with a particular workload. But if the Service doesn’t work as expected, or if networking issues prevent requests from reaching the replicas reliably, having replicas won’t necessarily improve performance.
- No persistent identities or state: On their own, ReplicaSets and Deployments don’t provide a persistent identity or state to workloads. You’d need to create a StatefulSet to gain those attributes.
- No control over node assignment: By default, ReplicaSets and Deployments don’t give you direct control over which nodes will end up hosting Pod replicas. You can control this behavior using taints and tolerations. But depending on what your goals are, a better approach may be to use a DaemonSet, which offers a more scalable way of deploying copies of Pods across all or most nodes within your Kubernetes cluster.
Monitoring, scaling, and rollouts: ReplicaSet vs. Deployment in action
When it comes to managing ReplicaSets as compared to Deployments, there are some differences to think about in the realms of monitoring, scaling, and rollouts:
- Monitoring: For both types of objects, you’ll want to monitor to make sure your requested Pods have been successfully scheduled and that none are stuck in the Pod pending state. But for ReplicaSets, there’s more to monitor because you need to track this data for each Pod replica.
- Scaling: You can use the kubectl scale command to add or remove replicas from both ReplicaSets and Deployments. The process is slightly more straightforward with ReplicaSets, however, because the workload already includes replicas from the start. Note, too, that both ReplicaSets and Deployments can scale to zero - meaning you remove all Pods from them, effectively shutting down the workload.
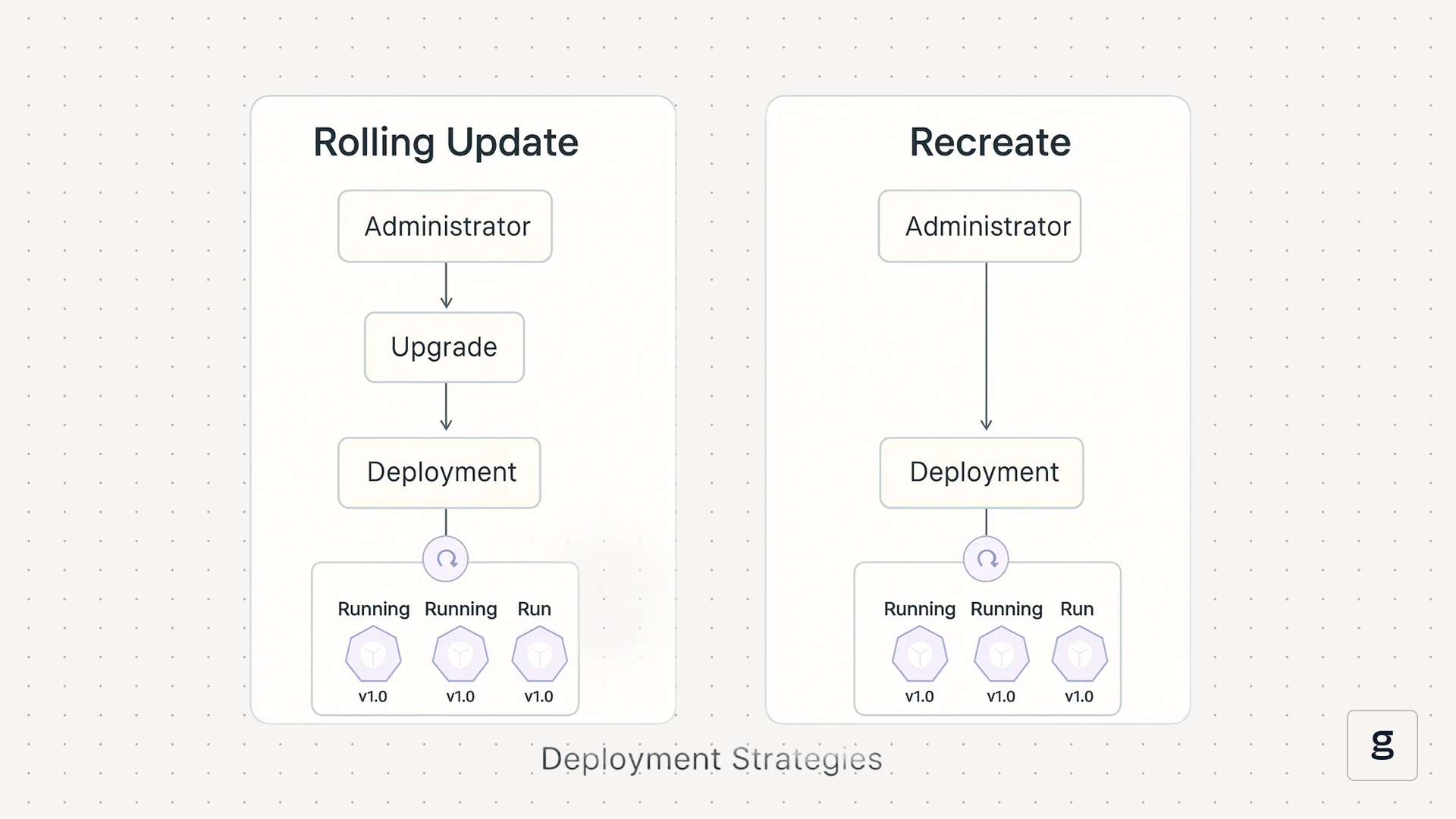
- Rollouts: As we’ve noted, Deployments give you the ability to define a deployment strategy, which specifies exactly how Kubernetes should add or remove copies of Pods from a workload. You can’t directly configure a deployment strategy as part of a ReplicaSet, although you can do this if you include a ReplicaSet within a Deployment that also has a deployment strategy definition.
Best practices for working with ReplicaSets and Deployments
Whether you choose to create a ReplicaSet, a Deployment, or both, the following best practices can help to optimize the performance and scalability of your workload:
- Only use replicas when you need them: Just because you can create a ReplicaSet doesn’t mean you should. In general, it’s best to stick with Deployments, which are simpler. Define replicas only when you have a use case that requires them.
- Assess cluster resource usage: Be sure your cluster can actually support the number of replicas you define by monitoring resource usage levels.
- Scale replicas dynamically: You’re not bound to the number of replicas you originally define. You can add or remove them as needs change via scaling. Scaling can help to optimize the balance between resource consumption and workload performance.
- Implement load balancing: We said it above, and we’ll say it again: Replicas are only effective if you distribute load effectively across them, which is why it’s critical to have a reliable load balancing setup if you use a ReplicaSet.
How groundcover accelerates visibility for ReplicaSets and Deployments
No matter which type of object you choose, groundcover has you covered when it comes to monitoring and observability. By continuously collecting performance data from all layers of your Kubernetes cluster - nodes, Pods, Deployments, ReplicaSets, Services, and everything else - groundcover clues you in quickly to problems like a mismatch between requested and existing Pods, or resource utilization problems that may cause replicas to fail.
.png)
We can’t tell you exactly how to configure your workloads - that’s up to you to decide, as Kubernetes admin - but we can give you the context you need to make informed decisions about optimizing workload performance and troubleshooting problems.
Choosing wisely between ReplicaSets and Deployments
ReplicaSets and Deployments are a little like peanut butter and chocolate: They often go well together, but you can use them separately from each other, too. Like a good baker, a good Kubernetes admin knows when and how to mix ReplicaSets and Deployments, and when to choose an entirely different workload deployment solution altogether.
FAQ
What are the main limitations of using a ReplicaSet directly instead of a Deployment?
The main limitation of a ReplicaSet, when used on its own instead of being part of a Deployment, is that it provides less control over the management of application updates and rollbacks. With a Deployment, you can take advantage of deployment strategies and automated rollbacks, which is not possible using a standalone ReplicaSet.
How does a Deployment manage versioning, roll-backs and updates compared to a ReplicaSet?
A Deployment manages Pod versions, Pod rollbacks, and Pod updates based on the configuration options specified in the Deployment, if they exist (if they don’t exist, Deployments will fall back on default behavior).
For example, if admins configure a Deployment to use rolling updates, Kubernetes will gradually replace older Pods with newer ones as part of the update process. This helps to reduce the risk of downtime compared to ripping-and-replacing all Pods at once.
ReplicaSets have no built-in mechanisms to control versioning, rollbacks, or updates. You can only use these configuration options if your ReplicaSet is part of a Deployment.
How does groundcover help teams visualise and troubleshoot ReplicaSet vs Deployment behaviours in production?
By continuously collecting data from all objects within a Kubernetes cluster, groundcover delivers the data and context that admins need to identify problems with both ReplicaSets and Deployments - such as failure to create a requested number of replicas, or a decline in the availability of resources due to having more replicas than a cluster can easily support.
Just as important, visualization features in groundcover help admins to make sense of all of their Kubernetes observability data. By viewing representations of all cluster resources and objects side-by-side, admins can more easily identify and troubleshoot problems in production.













.svg)