Zero Trust in Kubernetes: Principles, Architecture & Best Practices



Key Takeaways
- Zero trust means every request, API or service-to-service, must prove its identity and permissions, so a small breach doesn’t automatically spread across the cluster.
- The biggest risk isn’t initial access but what follows, as overly broad RBAC, unrestricted pod traffic, and shared identities can quickly turn one compromised workload into full cluster control.
- Practical controls like default-deny network policies, least-privilege ServiceAccounts, admission guardrails, and mTLS reduce blast radius without slowing delivery when rolled out in phases.
- Continuous monitoring, especially at the runtime and network level, is essential to catch “valid” workloads doing suspicious things and to verify that your zero-trust policies are actually working.
Traditional perimeter security assumes that “inside” the network is safer. That breaks down in Kubernetes because “inside” is constantly changing pods, services, identities, and network paths. By 2026, the complexity of these environments will have made zero trust a requirement; recent reports show that 89% of organizations experienced a Kubernetes security incident in the last year, often due to lateral movement after an initial pod compromise.
In Kubernetes, the real danger is not just initial compromise but what happens next. When one pod is compromised, too many RBAC permissions, unrestricted pod-to-pod traffic, and shared identities can turn a small breach into a big problem for the whole cluster. Historical breaches have shown how attackers can move sideways, stay in one place, and grow across nodes quickly.
This article explains what zero trust means in a Kubernetes environment, the architectural ideas behind it, and the real-world controls you can use to make the blast radius smaller without slowing down delivery.
What Is Zero Trust in Kubernetes?
Zero trust in Kubernetes means treating every component as untrusted by default and forcing every request to prove it should be allowed. Instead of “you’re inside the VPC so you are safe,” every request is authenticated, authorized, policy checked, and continuously monitored.
NIST describes Zero Trust Architecture in SP 800 207 as shifting defenses away from static perimeters and removing implicit trust based on network location.
A useful mental model is simple. Breaches happen, and your job is to limit what an attacker can do after they land. A compromised frontend should not automatically reach internal admin endpoints, scrape secrets, or traverse to databases just because it runs in the same cluster.
Zero Trust vs Traditional Kubernetes Security
Perimeter-based Kubernetes security usually emphasizes strong north-to-south controls, such as hardened Ingress and private API endpoints, but weaker east-to-west controls inside the cluster. Pod-to-pod traffic often stays broadly allowed unless a team invests heavily in segmentation.
A zero-trust security model flips that emphasis. It focuses on internal controls that make lateral movement and privilege escalation hard. The core idea is that network location is not a security boundary in a dynamic system like Kubernetes.
Why Kubernetes Needs a Zero Trust Security Model
This table breaks down how a single pod compromise escalates into a cluster-wide incident and how zero trust principles intervene:
Core Principles of Zero Trust Kubernetes
These principles are the rules you’ll apply across Kubernetes API access, service-to-service identity, segmentation, and ongoing monitoring to eliminate implicit trust and reduce blast radius:
Verify Every Request
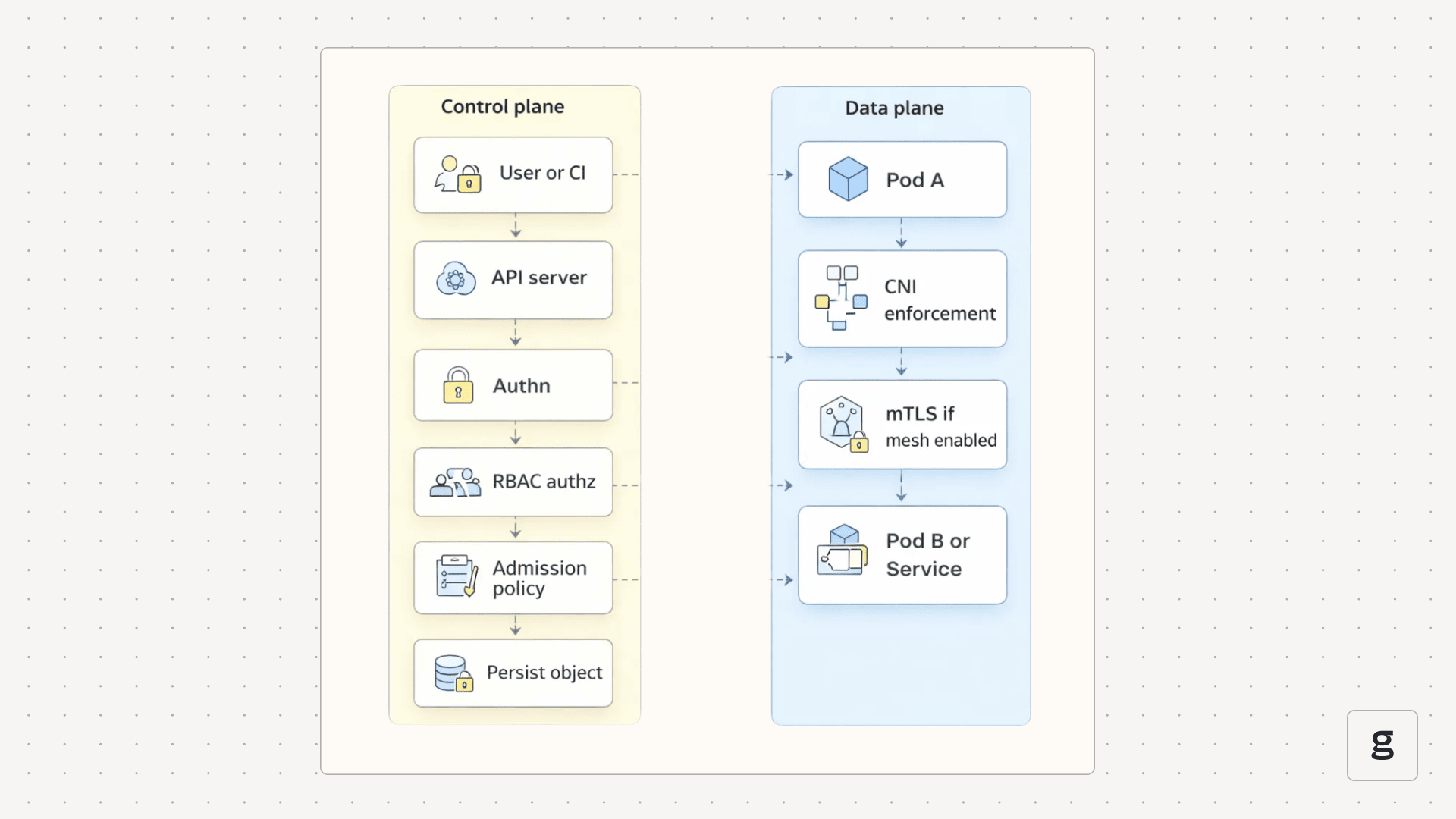
In Kubernetes, verification applies to the Kubernetes API and to service-to-service traffic.
For Kubernetes API changes, the API server checks authentication and RBAC authorization, then runs admission controls before persisting the object. Runtime pod-to-pod traffic is enforced separately in the data plane, for example, by a CNI enforcing NetworkPolicies. RBAC answers “are you allowed,” and admission controls answer “is this compliant before it is stored.”
For service-to-service traffic, you want workload identity so services prove who they are, not just where they come from. Service meshes such as Istio security concepts describe how mTLS and workload identity secure cluster communication and how policy can be enforced at runtime.
Enforce Least Privilege Access
Least privilege in Kubernetes is mostly about removing ambient authority.
- Use a distinct ServiceAccount per workload, not one shared account for many services
- Prefer Roles scoped to a namespace over ClusterRoles unless you truly need cluster-wide access
- Avoid wildcard verbs and resources, because they turn small mistakes into big incidents
Example RBAC tightening:
Aqua’s RBAC Buster write-up is a good “why” story here, because the attackers did not need an exotic exploit chain. They needed initial access plus overly permissive RBAC paths to persist and operate at scale.
Assume Breach and Minimize Blast Radius
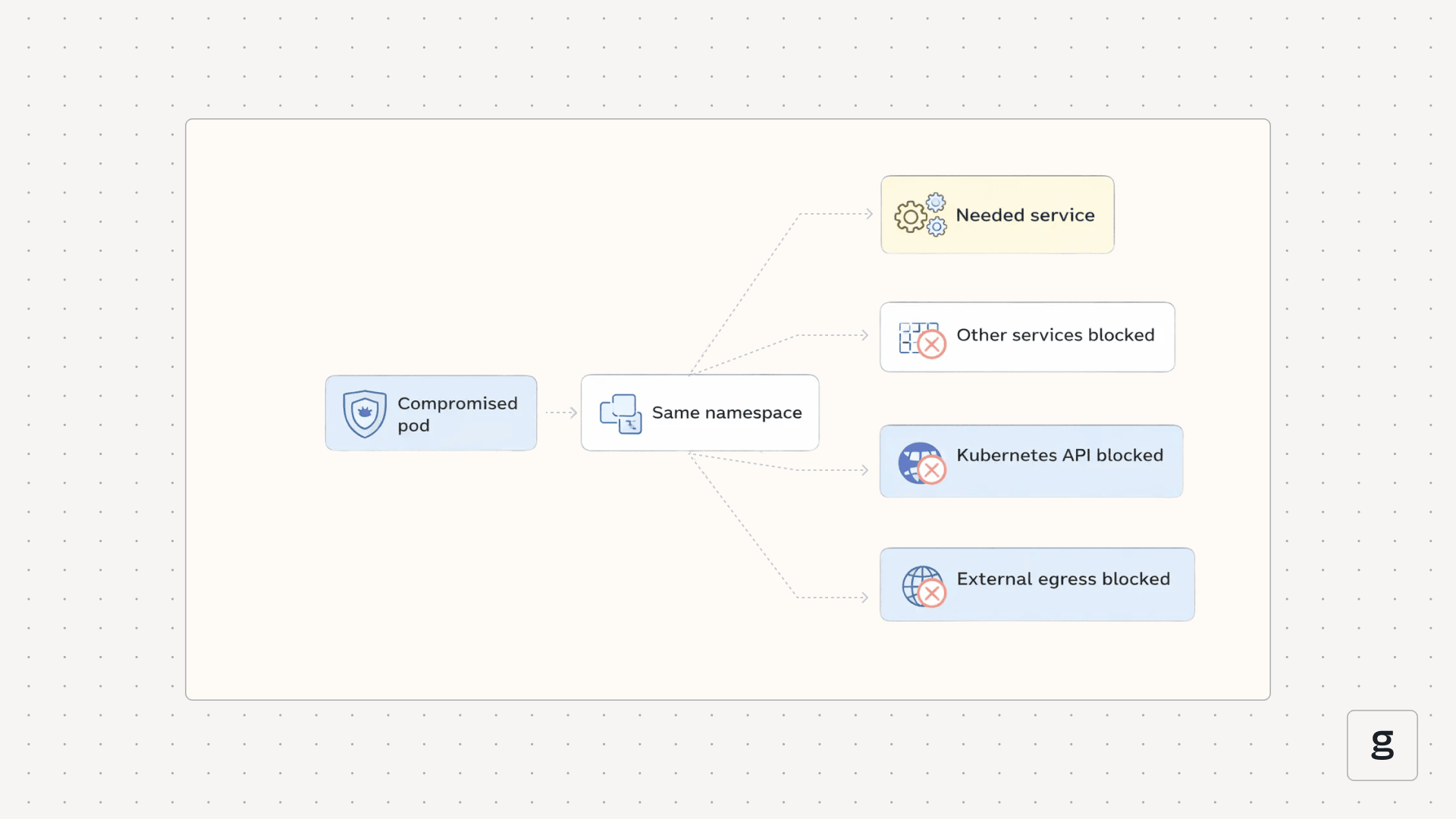
Assume breach forces you to segment and scope access.
A compromise in namespace A should not imply access to namespace B. A compromise in workload X should not imply access to data stores it does not need. A compromised CI job should not imply cluster admin.
Blast radius control usually comes from combining network policy, identity policy, and admission guardrails. If you only do one of these, you often leave an attacker an easy path around it.
Continuous Monitoring and Validation
Zero trust is not “authenticate once, trust forever.” It’s continuous. You watch audit logs for API access patterns, you check policy drift, and you monitor runtime behavior for abnormal process and network activity.
This matters because real incidents often look like valid pods doing invalid things, which is why runtime signals complement static controls.
Key Security Controls in Zero Trust Kubernetes
These are the concrete, “day-one” controls that turn zero trust from a mindset into enforceable guardrails across identity, networking, and runtime behavior in your cluster:
1. Identity and Access Control
Focus on these controls first because they define who can do what.
- Human access via a central identity provider using OIDC and SSO, with short-lived access for elevated permissions when possible.
- Workload identity via dedicated ServiceAccounts per workload, and avoid sharing tokens across deployments.
- Admission controls that stop risky specs from ever reaching the cluster, such as privileged pods and hostPath mounts.
2. Network Segmentation and Policy Enforcement
By default, Kubernetes allows pod-to-pod traffic unless you apply NetworkPolicies and your cluster uses a network plugin that actually enforces them. A zero-trust Kubernetes posture usually starts by removing implicit connectivity.
Start with a deny all baseline:
Then add explicit allows for the traffic you actually need, such as DNS egress and service-to-service flows. If you skip the deny all baseline, lateral movement stays easy.
3. Workload Security and Runtime Protection
Runtime controls help you detect and contain a compromised pod quickly. Look for unexpected process execution, scanning behavior, and unusual outbound network traffic. Tie these alerts back to Kubernetes metadata so a responder can act fast.
Zero Trust Kubernetes Architecture Components
Zero trust becomes real in Kubernetes when you translate principles into enforceable controls at the right chokepoints: identity, admission, and the network data plane. The components below are the building blocks teams typically combine to make that happen in production.
Service Mesh and mTLS
mTLS gives you encryption in transit and workload identity for service-to-service traffic. Istio documents how identity, authentication, and authorization work together in its security model. If you are planning a gradual rollout, use an incremental migration plan. The Istio mutual TLS migration guide is a good example of how teams phase this in without breaking production.
Kubernetes RBAC and Admission Controllers
Kubernetes RBAC and admission policies are where security teams prevent dangerous workloads from landing in the cluster. A practical starting point is a short policy set that blocks the biggest foot guns.
- Block privileged pods
- Require a restricted Pod Security posture where feasible
- Restrict image registries to approved sources
- Require basic metadata labels for ownership and environment
Network Policies
Network Policies are your segmentation layer. They are also one of the most commonly misunderstood features because policy objects can exist even if enforcement is not active. Validate that your CNI is enforcing policies in the namespaces you care about.
Policy as Code with OPA Gatekeeper
Policy as code is how you scale guardrails without turning every deployment into a manual review. OPA Gatekeeper-style policies can enforce constraints at admission time so risky specs get rejected with a clear message.
Implementing Zero Trust Kubernetes Step by Step
A successful zero trust rollout in 2026 follows a "Monitor-then-Enforce" lifecycle to avoid breaking production traffic.
Common Challenges in Zero Trust Kubernetes Adoption
The most common failure modes are predictable.
- Zero trust without egress controls still allows data exfiltration.
- NetworkPolicies are deployed but not enforced due to CNI misconfiguration.
- Service mesh is enabled but left permissive because mTLS alone does not equal authorization.
- RBAC sprawls with no ownership and no review automation.
- Policies that block deployments without clear explanations, which push teams toward bypasses.
Best Practices for Operating Zero Trust in Kubernetes at Scale
Operating zero trust at scale requires moving away from manual configuration toward "Security-as-Code" (SaC).
Strengthen Zero Trust Kubernetes with Unified eBPF-Based Observability from groundcover
Zero trust increases the number of policy edges, so troubleshooting becomes part of security. When a service cannot talk to another service, you need to quickly tell whether the root cause is an RBAC denial, a NetworkPolicy drop, a mesh authorization rule, or an admission policy issue.
Traditional observability often relies on sidecars or code instrumentation, which can be bypassed or tampered with. groundcover uses eBPF to collect signals directly from the Linux kernel, enabling deep visibility into network flows and process activity without requiring application changes. Furthermore, its BYOC deployment model ensures that your sensitive telemetry data never leaves your cloud perimeter, satisfying the strictest data sovereignty requirements of a zero-trust architecture.
An eBPF-based approach can correlate kernel-level signals like network flows and process execution with Kubernetes metadata. That helps validate segmentation and investigate runtime anomalies without adding code instrumentation everywhere.
If you are evaluating tools for this, you can start with groundcover’s BYOC model overview and then check pricing details, including the free tier and trials, to understand deployment constraints. If you want a deeper technical perspective, this guide on eBPF in Kubernetes explains why kernel-level collection is useful for Kubernetes observability, and the Kubernetes observability guide is a practical reference for signals and workflows.
m
Conclusion
Zero-trust Kubernetes is a security model built for dynamic infrastructure. It assumes compromise and forces every request, identity, and network path to prove it should exist.
If you start with deny-by-default segmentation, tighten role-based access control, and enforce policy as code with clear guardrails, you reduce blast radius without freezing delivery. The 2024 Red Hat report shows why that balance matters because incidents are common and the business impact is real.













.svg)